







PKU-DAIR實驗室成果亮相SOSP 2024:
支持并行熱切換的大模型訓練系統
第30屆“ACM操作系統原理大會”(SOSP: ACM Symposium on Operating Systems Principles)于2024年11月4日至6日在美國的德克薩斯州召開。SOSP與OSDI并稱為計算機系統領域兩個最高水平的學術會議,擁有50多年的悠久歷史。本次SOSP大會共有248篇論文投稿,43篇被接收,錄用率僅為17.3%。

PKU-DAIR實驗室論文《Enabling Parallelism Hot Switching for Efficient Training of Large Language Models》被計算機系統領域頂級會議SOSP 2024錄用,論文介紹了新型的支持并行熱切換的大模型訓練系統,系PKU-DAIR實驗室自研分布式深度學習系統河圖Hetu(https://github.com/PKU-DAIR/Hetu)圍繞大模型訓練的新成果。


論文介紹
關鍵詞
Distributed Training
Large Language Model
Parallelism Strategy
1、導讀
近年來,以ChatGPT為代表的大語言模型(Large Language Model, LLM)引起了廣泛的關注,它的性能提升得益于模型參數量、上下文和數據量的增長,同時也給系統優化帶來了更多的挑戰。現有系統通常假設工作負載是恒定的,從而采用靜態的并行策略組合來進行大規模的分布式訓練。然而,真實數據集的序列長度在不同樣本間差異較大,且大多呈長尾分布,本工作首次揭示了在這類長短文混訓的動態場景中,現有系統的靜態并行策略會大大拖慢短序列的訓練效率。
針對該問題,我們基于自研的分布式深度學習系統河圖Hetu,創新性地提出了首個支持并行熱切換的HotSPa系統,通過對mini-batch內的序列進行分組并使用不同的并行策略來最大化訓練效率。HotSPa利用熱切換技術完成模型權重、梯度在策略間的高效轉換和累積,在保證精度無損的前提下,最大化利用硬件內存和計算資源。實驗結果表明,與Megatron-LM、DeepSpeed等使用靜態并行策略的系統相比,HotSPa在不同規模的LLaMA2模型和不同上下文長度下,可以獲得2.99x的加速比。
2、背景和挑戰
近年來,大規模預訓練模型得到了快速的發展,它的性能提升得益于模型參數量、上下文和數據量的增長,同時也給系統優化帶來了更多的挑戰。現有的分布式訓練系統提出了一系列并行策略,從而能夠在多個設備中處理大規模的模型和數據。并行策略的選擇取決于如顯存占用、計算開銷、通信代價等工作負載,現有的方法通常假設工作負載是恒定的,因此在訓練過程中會使用靜態的并行策略組合。然而,在真實數據集中,不同樣本間的序列長度差異較大,導致了樣本間工作負載的不均衡,即使在一個mini-batch內部,這樣的現象也是相當顯著的,因此現有系統的靜態并行策略并不是最優解。
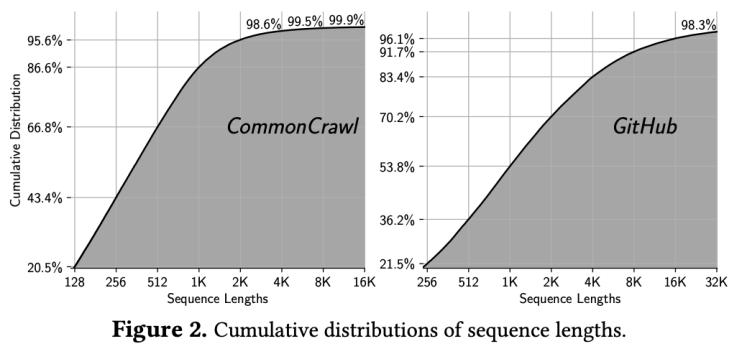
為了支持較長序列的訓練,通常需要采用更節省內存的并行策略以避免內存溢出。然而,對于短序列來說這類并行策略會引入大量不必要的通信開銷,導致效率低下。結合CommonCrawl和GitHub這兩個數據集的序列長度分布可以發現,雖然數據集中都包含長序列,但占比不高,以張量并行為例,可以看到隨著上下文的增加,需要增大TP以避免OOM,但與此同時,對于在數據集中占比大多數的短序列來說,更高的TP意味著更低的吞吐,從而拉低了整體的訓練性能。
總的來說,現有系統忽視了大模型訓練中樣本間工作負載不均衡的問題,只是簡單地使用靜態并行策略來處理。因此,我們嘗試從一個尚未被探索的方向來加速模型訓練過程:我們能否針對不同工作負載/序列長度的序列采用不同的并行策略?
3、HotSPa技術方案
方案概覽
根據上述發現,我們提出了HotSPa,一個支持并行熱切換的訓練系統,核心貢獻如下:
(1)首次提出并行熱切換的訓練范式:我們提出了一個基于并行熱切換的全新訓練范式,對每個mini-batch內的數據,我們會根據其工作負載的差異進行分組,并對每個分組使用最合適的并行策略,在任意兩組策略之間,我們的系統都會對模型參數和梯度進行自動、高效且無感的切換,并在模型更新前完成不同策略間的梯度累積,以保證訓練效果不受影響。
(2)統一的計算圖表示和編譯:現有的系統,如Megatron-LM和DeepSpeed,由于其復雜的系統設計,在訓練過程中僅支持一種固定的并行策略組合,從而無法對不同的序列負載使用不同的并行策略。而我們的工作設計了專門的圖編譯器(graph compiler),能夠用一張統一的邏輯圖同時表示多組不同的并行策略組合,并進一步編譯生成對應的多組可執行計算圖,共享模型狀態的存儲,從而才能支持復雜的并行熱切換語義。
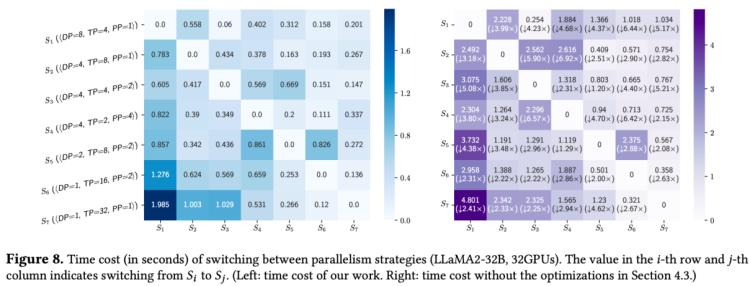
(3)并行熱切換技術:給定任意兩組不同的并行策略組合,它們之間的熱切換需要在不同的設備中交換模型的參數和梯度,不可避免地會引入額外的通信開銷。為了解決這個問題,我們設計了熱切換規劃器(hot switch planner),提出一種啟發式算法來尋找任意兩組策略之間的最優通信方案,并引入了一系列通信和顯存拷貝的優化技術來進一步降低切換開銷。
(4)HotSPa系統基于Graph Compiler和Hot Switch Planner,通過支持并行熱切換的訓練范式,與現有系統相比,可以獲得2.99x的加速比。

圖編譯器(Graph Compiler)
圖編譯器(graph compiler)支持用一張統一的邏輯圖同時表示多組不同的并行策略組合,并進一步編譯生成對應的多組可執行計算圖,且共享模型狀態的存儲。對應三個核心步驟:
(1)邏輯圖(Logic Graph):用統一的邏輯圖來表示多組不同的并行策略組合。
基于DTensor(Distributed Tensor, 分布式張量)架構,用DStates(Distributed States, 分布式狀態)來表示一組并行策略組合:用Splits, Partial, Duplicate來表示參數在不同設備中的切分方式,用DeviceGroup來表示不同的參數切片和設備的映射關系。

用DStates表示并行策略
為了同時表示多組分布式策略,本工作創新性地將一個DTensor與多組DStates綁定,并支持在整張計算圖上同時進行多組分布式狀態的推導。具體來說,令每個參數和輸入變量都同時綁定多組DStates,并在構建邏輯計算圖的過程中,每個算子都會同時對這多組DStates進行推導,并自動插入中間算子以保證功能的完整性。
由于不同的并行策略組合,通過推導DStates所得到的計算圖并不一定相同(如下圖step1)。為了能夠用同一張計算圖表示這多組策略,會通過自動插入空算子(dummy op)來處理不同策略在通信等中間算子上的差異(如下圖step2)。
通過上述方案,本工作支持了用統一的邏輯圖來表示多組不同的并行策略組合。

step1:兩組不同的并行策略,對應兩組不同的計算圖

step2:通過引入dummy op,使得兩張計算圖的表現形式一致

step3: 將兩張計算圖用同一張邏輯圖來統一表示
(2)可執行圖(Exec Graphs):基于統一的邏輯圖編譯、生成多組可執行計算圖,每組可執行計算圖都對應一組獨立的并行策略組合,它們之間共享同一份模型狀態存儲。
邏輯圖只是一種抽象表示,為了能夠編譯、生成真正可執行的分布式計算圖,編譯器會進行算子的插入、合并、剪枝、替換、重排等操作:
- 插入fp32->bf16的類型轉換算子、梯度累積算子。
- 合并相鄰的comm op和fusion op。
- 剪枝不必要的dummy op和類型轉換、梯度累積、梯度通信算子。
- 替換所有的comm op,生成對應的集合通信算子或點對點通信算子。
- 重排計算圖局部拓撲,實現計算和通信的重疊(overlap)。
下圖給了將一個邏輯圖轉化為兩組可執行圖(兩組并行策略組合)的具體例子:

邏輯圖(左上角):編譯、生成兩組可執行計算圖(左下角,右側)
(3)編排可執行圖(Orchestrate Exec Graphs):基于Hot Switch Planner給出的代價分析,編排這些可執行圖(并行策略組合)的執行順序,以最小化存儲和通信的開銷。
選取初始化圖(instantiation graph):選取最小化模型狀態(model states)存儲的策略對應的可執行圖作為初始化圖。(以下圖為例,選取TP2,PP2為初始化圖)
重排可執行圖(executable graph):基于Hot Switch Planner給出的任意兩組策略間熱切換的代價,確定不同策略執行的先后順序,以最小化整體的熱切換代價。(以下圖為例,tp2pp2->dp4->dp2tp2,只有第一次熱切換需要引入額外的通信代價,其余只需要本地切分即可)
剪枝&梯度累積:除初始化圖之外,其余可執行圖需要剪枝不必要的類型轉換算子(type casting op)、參數更新算子(update op)等,從而保證只在初始化圖上做模型的更新,在其他可執行圖上僅作梯度累積,確保模型的精度不受影響。

選取tp2,pp2為初始化圖,重排可執行圖順序為:tp2,pp2->dp4->dp2,tp2
熱切換規劃器(Hot Switch Planner)
HotSPa支持將一個mini-batch內的數據按照序列長度進行分組,每組采用不同的并行策略(對應不同的可執行計算圖),不同策略的梯度會累積到同一個梯度緩沖區(grad buffer)中以保證模型收斂不受影響。
在兩組不同的并行策略之間,HotSPa會自動對模型的權重和梯度進行熱切換,而熱切換規劃器(Hot Switch Planner)的核心作用就是推導出任意兩組不同的并行策略之間切換代價最小的通信方案,具體來說,分為以下2個核心步驟:
(1)基于啟發式算法建模熱切換(Model Hot Switching)
通信方案存在多個可行解:熱切換指分布式狀態的切換(從初始策略->目標策略),需要在整個集群中對模型的參數和梯度進行重新劃分,是一個多對多的復雜通信,由于數據并行的存在,同一個模型切片在不同設備中存在多份重復的拷貝,對應的發送方并不唯一,因此對于通信方案來說存在大量的可行解。
通信的基本單位-模型切片:對于任意一個模型參數或梯度來說,整體可以看作是一個全局的抽象的ParamBlock。每個ParamBlock會根據并行策略所對應的分布式狀態被劃分成多個ParamSlice,由于數據并行的存在,同一個ParamSlice可能被多個設備同時擁有。對于任意兩組并行策略(如下圖中的src策略和dst策略),它們對ParamSlice劃分的交集,被定義為熱切換通信的基本單位-模型切片。

通信的基本單位:兩組并行策略對ParamSlice劃分(左側)的交集(右側)
熱切換問題定義:假設從當前策略熱切換到目標策略,則對任意一個模型切片,遍歷目標策略中需要該切片的每個設備(needed devices),并從當前策略中擁有它的所有設備里(owned devices)選擇最合適的發送方。

啟發式算法:基于兩個基本原則,我們提出了一種啟發式的搜索算法,從而能夠尋找最合適的熱切換通信方案。
- 原則一:節點內通信優于節點間通信。在傳統的GPU集群中,節點內的GPU是通過NVLink進行鏈接通信的,相比于節點間走Infiniband或以太網的跨機通信,具有更高的通信帶寬。因此,如果存在機內或機間等多個不同設備擁有同一個模型切片,則優先考慮節點內的設備作為發送方。
- 原則二:GPU的連接鏈路是全雙工的。現代的網絡鏈接對于數據的發送和接收通常具備獨立的通信帶寬,因此對于任意設備來說,同時進行數據的收發并不會影響通信效率。事實上,由于每個設備需要接收的數據量是固定的(由切換的目前策略決定),不可能減少,只可能讓不同設備的數據發送量盡可能負載均衡。即最小化所有設備的數據發送量中的最大值。

基于上述兩個基本原則,熱切換通信方案推導的啟發式算法流程如下:
- step1: 對每個設備device i,記錄機內通信量Vi(intra)和機間通信量Vi(inter).
- step2: 遍歷每個模型參數/梯度切片 slice,基于當前策略和目標策略的分布式狀態來確定擁有該切片的設備集合S(owner devices),和需要該切片的設備集合D(target devices).
- step3: 遍歷集合D中的每個設備dst,根據機內和機間的差異將集合S中的設備劃分為S(intra)和S(inter),基于原則一,優先考慮機內設備S(intra),如果為空,則考慮機間設備S(inter).
- step4: 基于原則二,從候選的設備集合中,貪心地選取當前數據發送量最小的設備作為模型切片的發送方,即src ← arg mini {Vi (intra) or (inter) | i∈S(intra) or (inter)};同時更新該發送方對應的通信量,即Vsrc(intra) or (inter) ← Vsrc(intra) or (inter) + sizeof(slice).
(2)優化熱切換開銷:Message Fusion & Layout Optimization
熱切換不可避免地會帶來額外開銷,包括通信開銷和顯存拷貝開銷,這里利用消息合并(Message Fusion)和布局優化(Layout Optimization)這兩項技術進行專門優化。
消息合并(Message Fusion):將發送給同一個設備的數據都合并到連續的發送緩沖區(send buffer)里,同理,將從同一個設備接收的數據合并到連續的接收緩沖區(recv buffer)里,從而能夠合并多個p2p send/recv,減少p2p kernel的調用次數,還能增大單次通信的數據量大小,提高帶寬利用率和通信效率。此外,通過NCCL提供的BatchedSendRecv原語,支持不同的send/recv buffer對應的p2p send/recv并行傳輸。

布局優化(Layout Optimization):為了避免引入contiguous算子和concat算子導致用kernel進行訪存和數據搬運,引入過高的拷貝開銷,這里將縱向切分的權重/梯度在布局上也按照橫向切分排布。此時大部分的非連續的內存訪問都可以轉化為連續的內存訪問,從而可以將大部分比較耗時的contiguous算子和concat算子直接轉化為訪存代價非常小的cudaMemCpy。具體計算時,只需要將改變gemm kernel的layout參數即可保證數學上的等價性。

4、實驗效果
HotSPa是首個支持并行策略動態熱切換的大模型分布式訓練系統,相比現有的只支持靜態并行策略的系統(如Megatron-LM,、DeepSpeed),HotSPa能更靈活地支持和適應負載動態變化的場景,在現有的大多數長短序列分布不均衡的數據集中,能夠獲得更高的訓練吞吐。
實驗設置:在實驗中,我們將HotSPa和現有的兩個分布式訓練系統Megatron-LM(DP+TP+PP+SP)、DeepSpeed(Zero1/2/3+Ulysses)在不同負載下進行了比較。在實驗環境上,使用4臺GPU服務器,每臺服務器上有8張A800-80G,機內NVLink的通信帶寬為400GB/s,機間IB通信帶寬為200GB/s。在模型上選用了開源的LLaMA2,包括三種不同規模的參數量:7B、13B和32B。在數據集上選擇了兩個開源且被廣泛使用的數據集CommonCrawl和GitHub。
端到端實驗:在GPU數量為8卡~32卡,模型規模為LLaMA2-7B~32B,最大序列長度為4k~32k的不同規模上進行實驗,在GitHub和CommonCrawl兩個數據集上,HotSPa相對于Megatron-LM分別取得最多1.5x和2.99x的加速比,相對DeepSpeed分別取得最多2.6x和5x的加速比。

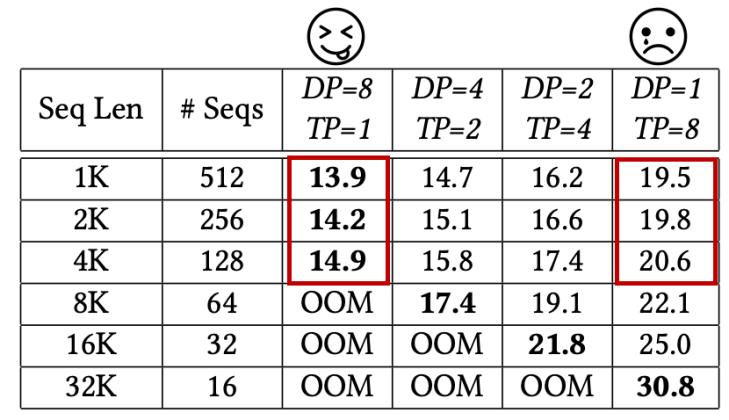
熱切換代價實驗:以LLaMA2-32B在32卡GPU上的測試結果為例,單次熱切換的時間開銷基本可以被優化至1s以內,相對于單個step的訓練時間,熱切換代價占比可以被忽略不計。
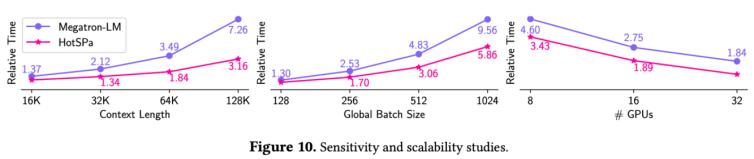
可擴展性實驗:Context Length: Megatron-LM的短序列被迫使用長序列的并行策略,因此上下文長度越長,HotSPa的加速比越大。GBS: Megatron-LM的時間基本隨全局批次大小線性增長,而對HotSPa性能表現更優,因為隨著長序列數量增加,對應分組的pp bubble減少,會進一步獲得加速。GPUs:兩個系統都具有良好的擴展性。
5、結語
在這個工作里,我們首次提出現有框架的靜態并行策略不適用于輸入序列長短變化的動態場景的缺陷,并創新性地搭建了一套支持熱切換訓練系統HotSPa。HotSPa實現于PKU-DAIR實驗室自研的分布式深度學習系統-河圖Hetu(https://github.com/PKU-DAIR/Hetu)。除了性能上的優勢,Hetu還有其他系統所不具備的高動態性和高靈活性。目前我們的系統已經全面開源,歡迎大家關注!

實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文100余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0