







近幾年,大語言模型(LLMs)無疑是人工智能發展過程中最為熱門的話題之一。這些模型以其強大的語言生成和理解能力,正在深刻改變著自然語言處理(NLP)領域的研究和應用方向。Human-Centric Intelligent Systems(HCIN) 作為一本致力于傳播以人為本的智能系統的所有理論和實際應用的最新研究成果的期刊,為這一領域的研究提供了重要的平臺。
為了幫助學者更好地了解大語言模型在不同領域的最新進展,HCIN期刊編輯部精心篩選了一系列高質量文章。這些文章涵蓋了AI成癮性與依賴性、跨語言機器翻譯錯誤分析等研究方向。這些文章不僅展示了大語言模型在不同應用場景中的潛力,也揭示了其在實際應用中可能面臨的挑戰和問題。希望本次的好文推薦能為學者的科研工作帶來啟發,推動以人為本的智能系統領域的進一步發展。
1、Can ChatGPT Be Addictive? A Call to Examine the Shift from Support to Dependence in AI Conversational Large Language Models
作者:Ala Yankouskaya, Magnus Liebherr & Raian Ali
DOI:https://doi.org/10.1007/s44230-025-00090-w
研究動機:
隨著人工智能技術的快速發展,尤其是像ChatGPT這樣的大型語言模型(LLMs)在日常生活中的廣泛應用,人們對其潛在的成癮性問題產生了關注。本文旨在探討AI對話模型從支持性工具轉變為依賴性工具的可能性,分析其對用戶行為和心理的影響,以期為合理使用AI提供理論依據。
研究方法與發現:
本研究采用文獻綜述和案例分析相結合的方法,對ChatGPT等AI對話模型的使用場景和用戶反饋進行深入分析。研究發現,AI對話模型的即時性和交互性可能引發用戶的過度依賴,尤其是在信息獲取和情感支持方面。此外,研究還發現,用戶對AI的過度依賴可能導致對人類社交互動的忽視,甚至產生心理上的依賴感。
研究結論:
研究表明,AI對話模型如ChatGPT具有潛在的成癮性,特別是在長時間使用和高強度依賴的情況下。這種依賴可能對用戶的社交能力和心理健康產生負面影響。因此,建議用戶在使用AI對話模型時保持適度,同時開發者應考慮設計更合理的使用機制,以減少成癮風險。
2、Error Analysis of Pretrained Language Models (PLMs) in English-to-Arabic Machine Translation
作者:Hend Al-Khalifa, Khaloud Al-Khalefah & Hesham Haroon
DOI:https://doi.org/10.1007/s44230-024-00061-7
研究動機:
隨著全球互聯性的增強,跨語言交流變得日益重要,尤其是對于使用非拉丁字母腳本的語言,如阿拉伯語。然而,英語與阿拉伯語之間由于結構和腳本差異巨大,機器翻譯仍面臨獨特挑戰。盡管預訓練語言模型(PLMs)在自然語言處理(NLP)研究中處于前沿,顯著提升了機器翻譯能力,但它們在英語到阿拉伯語的翻譯中仍難以達到高準確性和流暢性。這阻礙了英語和阿拉伯語文化之間的有效溝通與合作。
研究方法與發現:
本研究采用自動評估指標(chrF、BERTScore、COMET)和人工評估(使用MQM框架)來比較Google Translate和五種PLMs(Helsinki、Marefa、Facebook、GPT-3.5-turbo和GPT-4)的翻譯表現。研究涵蓋了心理學、政治、醫學和科學等不同文本領域,以全面評估模型在多樣化內容中的翻譯能力。結果顯示,Google Translate在所有評估的機器翻譯系統中表現最為穩健,總錯誤數最少。而Helsinki的錯誤數最多,表明其翻譯機制存在顯著挑戰。誤譯是所有平臺上最常見的錯誤類型,突顯了機器翻譯中實現準確和上下文相關翻譯的復雜性。
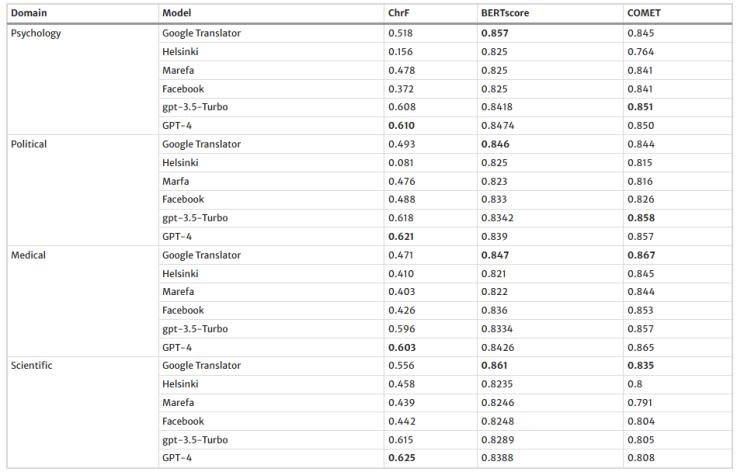
表1-MT自動評估結果

表2-不同翻譯系統的錯誤率
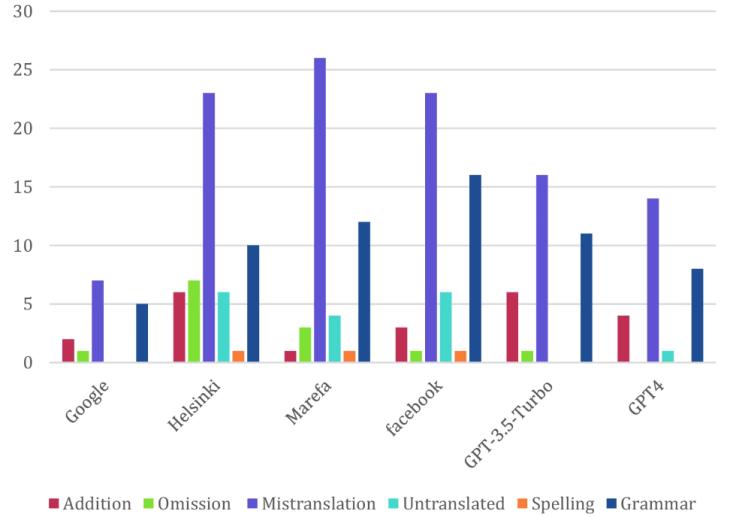
圖1-機器翻譯系統中的翻譯錯誤計數和主要類別的分布
研究結論:
研究表明,盡管預訓練語言模型在提升機器翻譯質量方面展現出積極成果,但它們在處理阿拉伯語語法和詞匯時仍存在局限性。這些模型在翻譯復雜句法和詞匯時容易出現錯誤,影響翻譯的準確性和流暢性。研究強調了繼續研究定制架構、多語言表示、上下文編碼和專門模型訓練的必要性,以進一步提升英語到阿拉伯語翻譯的性能

掃碼閱讀原文
3、The Linguistic Feature Relation Analysis of Premise and Hypothesis for Interpreting Nature Language Inference
作者:Xinyu Chen, Lin Li, Mengjing Zhang & Rui Zhang
DOI:https://doi.org/10.1007/s44230-023-00054-y
研究動機:
自然語言推理(NLI)任務是自然語言處理中的一個重要領域,旨在判斷兩個句子之間的邏輯關系(如蘊含、矛盾或中性)。然而,現有的NLI模型雖然在性能上取得了顯著進展,但其預測過程往往缺乏可解釋性。本文旨在引入前提和假設之間的語言特征關系的逐樣本分析,探索指導 NLI 建模和解釋能力。
研究方法與發現:
本文提出了一種基于多層注意力機制的NLI模型,通過分析前提和假設之間的語言特征關系來增強模型的可解釋性。研究者們在SNLI數據集上進行了實驗,驗證了多層連接機制的有效性。實驗結果表明,該模型不僅能夠以92.2%的準確率進行預測,還能以更接近人類解釋的方式展示其推理過程。通過逐層分析語言特征關系,模型能夠更清晰地解釋其預測依據。
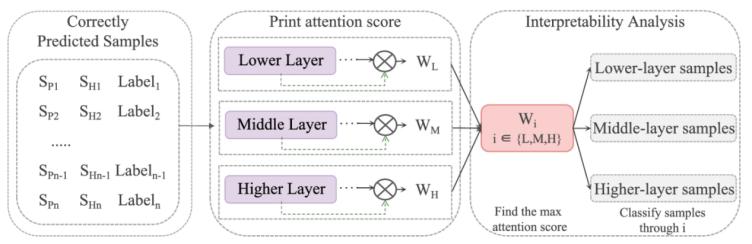
圖1-推理樣本過程
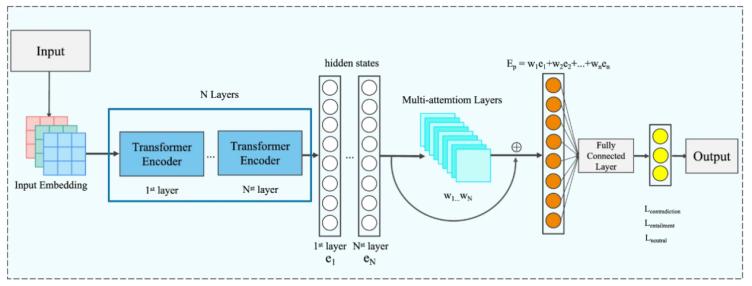
圖2-多層互聯 NLI
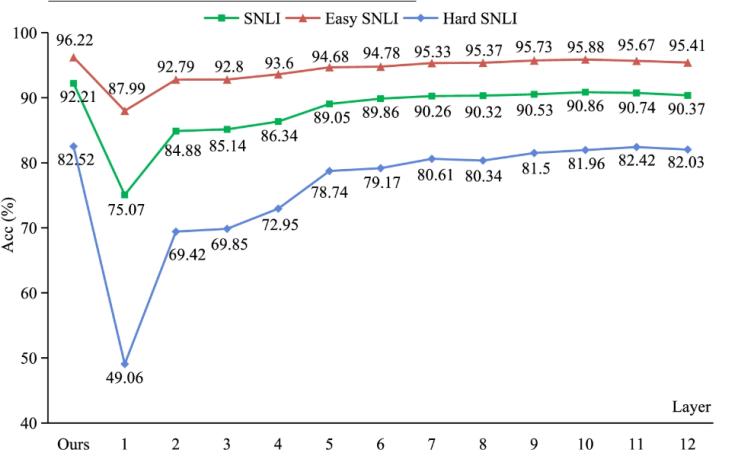
圖3-每一層的預測準確率(%)結果
研究結論:
本文重點介紹通過添加多層連接機制來解釋具有語言特征關系的NLI任務。我們的實證研究表明,語言特征關系可以幫助NLI模型以人類解釋的方式解釋預測過程。在SNLI數據集上進行的實驗結果表明,基于多層注意力的NLI模型可以以92.2%的準確率做出更大的可解釋性。在未來的工作中,我們將增加樣本的數量,以進一步驗證句子對中的語言結構。此外,對于低層、中層和高層捕獲的語言特征關系,我們將嘗試通過逐層基于提示的訓練來做出預測。
關于期刊

Human-Centric Intelligent Systems(eISSN:2667-1336)是一本國際化的,經過嚴格同行評審的開放獲取期刊,致力于傳播 “以人為中心的智能系統” 中所有相關理論和實際應用的最新研究成果,并提供以人為中心的計算與分析領域的前沿理論和算法見解。為了鼓勵科研成果的傳播,本刊暫不收取文章處理費。
期刊主編:西南交通大學李天瑞教授與澳大利亞悉尼科技大學徐貫東教授
顧問委員:東京大學教授,日本國家信息研究所所長Masaru Kitsuregawa與伊利諾伊大學芝加哥分校Philip S. Yu教授
|
投稿咨詢: HCIN期刊編輯部 Tel:17320182488 郵箱:hcin@editorialoffice.cn |
|



評論 0