







轉載自:微信公眾號 |專委會秘書處 CCF數據庫專委
公眾號文章鏈接:https://mp.weixin.qq.com/s/9ZF3TyBGETb26wgnMOx0MQ
Few-Shot Relation Prediction of Knowledge Graph via Convolutional Neural Network with Self-Attention
Data Science and Engineering (DSE)是由中國計算機學會(CCF)主辦,數據庫專業委員會承辦,施普林格·自然(Springer Nature)集團出版的開放獲取(OA)期刊。本篇文章精選自DSE第2023年第8卷第4期發文,由中新賽克贊助文章處理費。
文章介紹
知識圖譜(Knowledge Graph, KG)已經成為智能問答和推薦系統等多種應用的重要基礎。然而,KG中的某些關系僅包含有限的相關三元組,使得小樣本關系預測方法成為亟待研究的問題。目前基于KG嵌入(Knowledge Graph Embedding)的方法需要足夠的訓練三元組來學習實體和關系的表示,而最近的一些研究工作引入實體的鄰居和上下文等背景信息、學習小樣本場景中的實體和關系特征,但部分場景中的背景信息并不可用。從實際應用的角度看,可觀察到的少量三元組中包含著未被完全利用的屬性特征。因此,KG的小樣本關系預測仍面臨兩個方面的挑戰:如何描述實體和關系間的相關性,如何從觀察到的少量三元組中學習實體的隱藏屬性特征?為解決上述研究工作存在的問題,本文提出基于自注意力卷積神經網絡的KG關系預測(Convolutional Neural Network with Self-Attention Relation Prediction, CARP)模型,用于預測新的關系事實,如圖1所示。首先,為了學習關系的屬性特征,本文利用CNN從少量觀察到的三元組中構建具有自注意力的特征編碼器,通過賦予所觀察到三元組的不同權重來描述它們之間的相關性,以凸顯其屬性特征。進一步,通過將觀察到的三元組集合與數字圖像的不可分割性及平移特征不變性進行類比,構建特征編碼器,將CNN與基于自注意力的相關性相結合,學習關系的屬性特征。然后,利用嵌入網絡融合所學習到的特征,學習三元組的表示向量。最后,本文給出CARP模型的損失函數和訓練算法。本文的主要貢獻總結如下:
(1)提出從觀察到的少量三元組中學習屬性特征的方法,以增強關系表示。
(2)通過限制屬性特征空間,給出CARP模型訓練的損失函數。
(3)在3個數據集上進行了對比實驗,結果表明,CARP模型能有效完成KG的小樣本關系預測任務,且優于最優的對比模型。
模型框架
CARP模型包括用于學習屬性特征的特征編碼器、以及用于匹配觀察到的不完整三元組的匹配處理器兩個模塊,模型框架如圖1所示。
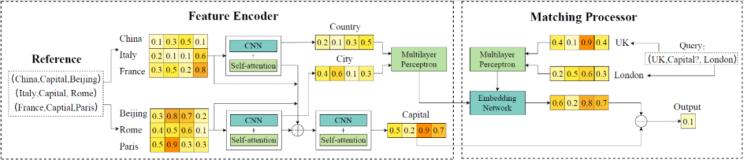
圖1. CARP模型框架特征編碼器模塊旨在挖掘具有相同關系的多個三元組中頭實體和尾實體共享的屬性特征,以及頭尾實體對共享的關系屬性特征,從而生成并選擇正確的三元組。首先將實體和關系的表示映射到特征向量空間,并使用可縮放點積計算注意力權重。然后使用L層CNN學習屬性特征,進一步利用高斯分布表示其概率分布,通過重參數化策略對特征進行采樣,獲得屬性特征的最終表示。匹配處理器模塊旨在將參考集中的頭尾實體間的相關性映射到查詢集中,利用向量距離對頭尾實體及關系進行聚類,從而得到最可能的實體關系、完成關系預測。
實驗效果
本文在NELL-One、FB-One和Wiki-One三個數據集上對提出的CARP模型進行了實驗測試,其中,NELL-One基于通過智能代理從新聞中收集結構化知識的NELL系統,Wiki-One基于由百科全書式知識構成的通用結構化知識庫Wikidata。此外,本文使用類似方法從社交知識所構成的大型協作知識庫Freebase中提取數據,構建了FB-One數據集。具體而言,首先排除逆關系,然后從每個關系中選擇50~500個三元組,作為小樣本關系預測任務的數據集,每個小樣本關系預測任務由與其對應、具有相同關系的三元組構成。在這3個數據集上,分別包含67、131和183個小樣本關系預測任務。本文將小樣本關系預測任務的訓練集、測試集和驗證集按照51/5/11、98/11/22和133/16/34的比例劃分。表1給出以上數據集的統計信息。

表1. 數據集統計信息首先,我們在3個數據集上進行3/5-shot關系預測,MRR、Hits@1、Hits@5和Hits@10等指標的測試結果如表2所示。本文提出的CARP模型在3個數據集上的各項指標均有顯著提升,與第二高的對比模型相比分別提高了90%、124%、70%和48%。實驗結果表明,CARP模型可適用于不同的數據集,在小樣本場景中可通過挖掘屬性特征而學習到更有效的實體表示。
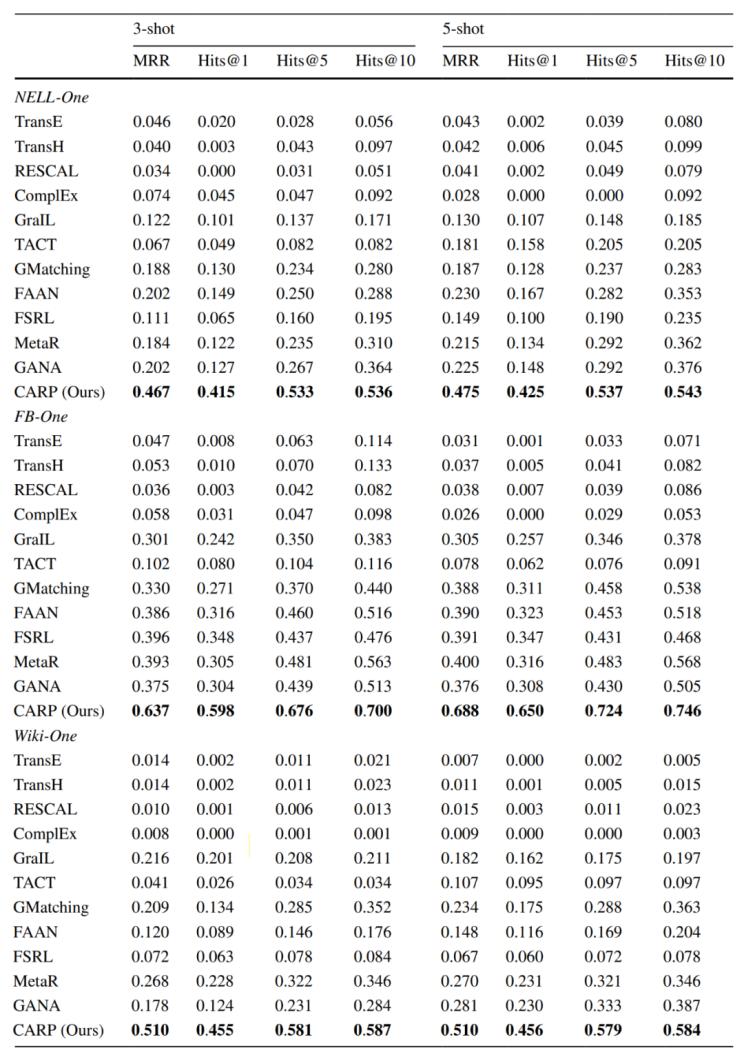
表2. 3/5-shot關系預測的MRR/Hits@1/Hits@5/Hits@10指標結果
為了評估樣本數量k的影響,設置了k=1、3、5、7,并使用不同的k值測試MRR指標,如圖2所示。結果表明,CARP模型在3個數據集上的MRR指標都優于對比模型,驗證了CARP模型對于小樣本關系預測任務的有效性。隨著k值的增加,MRR值略有增加,表明隨著參考集數量的增加,CARP模型能獲得更加豐富的信息。
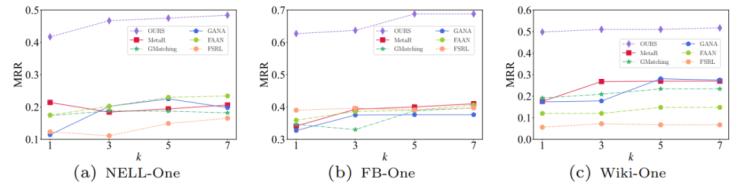
圖2. CARP模型性能隨樣本數量變化本文進一步通過消融實驗測試特征編碼器和匹配處理器的有效性。為測試特征編碼器的有效性,在參考集上使用平均池化層替換特征編碼器模塊(記為AS_1);為測試使用特征編碼器學習到的屬性特征對查詢處理的有效性,使用隨機特征替換屬性特征并作為嵌入網絡的輸入(記為AS_2),如表3所示。結果表明,特征編碼器和匹配處理器在CARP模型中能有效提升模型的效果,從觀察到的少量三元組中學習到的屬性特征在小樣本關系預測中起著至關重要的作用。
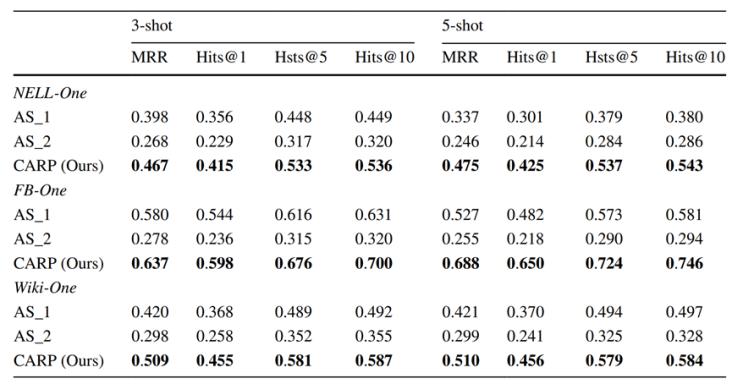
表3. 消融實驗MRR/Hits@1/Hits@5/Hits@10指標結果最后給出案例分析,在3個數據集上測試了不同小樣本關系預測任務的MRR指標,如圖3所示。結果表明,CARP模型在3個數據集上都具有穩定的表現,驗證了本文提出的CARP模型針對不同小樣本關系預測任務的可靠性,在接近80%的小樣本關系預測任務中達到了最佳MRR,表明本文模型對不同小樣本關系預測任務的魯棒性。
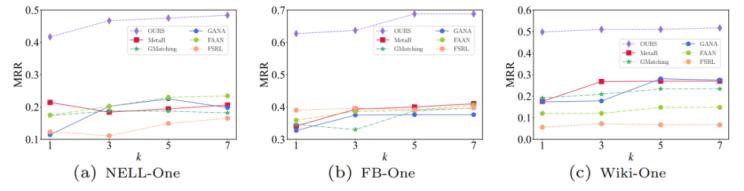
圖3. 不同關系預測任務上的MRR
結語
文提出CARP模型,有效預測觀察到的少量三元組中的新關系,模型專注于從少量三元組中學習關系的屬性特征,可有效避免引入背景信息而帶來的噪聲。CARP模型不僅增強了關系的表示,還有助于在小樣本場景中預測新的關系事實。
作者簡介

鐘姍娜,碩士,于2023年獲得云南大學計算機科學與技術專業碩士學位。主要研究方向為大數據分析、知識圖譜。

王笳輝,博士,于2023年獲得云南大學計算機科學與技術專業博士學位。在KBS、ESWA、DSE、《軟件學報》和《電子學報》等期刊和會議發表論文10篇。主要研究方向為知識圖譜、概率圖嵌入。

岳昆,博士,云南大學信息學院教授、博士生導師、副院長、云南省智能系統與計算重點實驗室主任。入選“興滇英才支持計劃”云嶺學者,云南省杰青、中青年學術和技術帶頭人。主持國家自然科學基金重點項目等科研項目20余項。在TSC、TCYB、TIST、《計算機學報》、《軟件學報》、AAAI、UAI、CIKM和ICWS等期刊和會議發表論文100余篇。授權發明專利20余項,出版著作5部、參編譯著1部。主要研究方向為海量數據處理、大數據知識工程、貝葉斯深度學習。

段亮,博士,云南大學信息學院副教授、碩士生導師。于2019年獲得北京航空航天大學計算機科學與技術專業博士學位。入選“興滇英才支持計劃”青年人才和云南大學“東陸青年學者”,主持國家自然科學基金青年項目等科研項目5項,在TKDE、KAIS、《軟件學報》、AAAI 、ICDM、UAI和WSDM等期刊和會議發表論文20余篇。主要研究方向為海量數據處理、機器學習、社交網絡分析。

孫正寶,博士,高級實驗師、碩士生導師。2021年獲得云南大學信息與通信工程專業博士學位。入選“興滇英才支持計劃”青年人才,主持完成國家自然科學基金青年項目等科研項目3項。主要研究方向為地理時空數據挖掘。

方巖,碩士,助理研究員。于2020年獲得云南大學計算機科學與技術專業碩士學位。主要研究方向為數據挖掘、知識圖譜。
期刊簡介

Data Science and Engineering(DSE)是由中國計算機學會(CCF)主辦、數據庫專業委員會承辦、施普林格 自然(Springer Nature)出版的Open Access期刊。為了迎合相關領域的快速發展需求,DSE致力于出版所有和數據科學與工程領域相關的關鍵科學問題與前沿研究熱點,以大數據作為研究重點,征稿范疇主要包括4方面:(1)數據本身,(2)數據信息提取方法,(3)數據計算理論,和(4)用來分析與管理數據的技術和系統。
目前期刊已被EI、ESCI與SCOPUS收錄,2022年CiteScore為8.8,影響因子(Impact factor)為4.2,在計算機科學應用領域排名前13%(102/792)、計算機軟件領域排名前16%(65/404)、信息系統領域排名前16%(60/379),人工智能領域排名前19%(58/301)。稿件處理費由贊助商中新賽克(Sinovatio)承擔,歡迎大家免費下載閱讀期刊全文,并積極投稿。
原文鏈接:
https://link.springer.com/article/10.1007/s41019-023-00230-x
文稿:李博涵、王曉黎、王肇國排版:李瑞遠審核:專委會秘書處


CCF數據庫專委


評論 0