 548
548
 0
0
 2025-06-22
2025-06-22
 2025-06-22
2025-06-22

該論文發表于International Conference on Learning Representations 2025(CCF A),題目為《BrainUICL: An Unsupervised Individual Continual Learning Framework for EEG Applications》。
浙江大學的周陽軒為此文第一作者,浙江大學的趙莎研究員為此文的通訊作者。
論文鏈接:https://openreview.net/pdf?id=6jjAYmppGQ
腦電圖(EEG)是一種非侵入式腦機接口技術,在臨床診斷、睡眠階段識別、情緒識別等領域有廣泛應用。然而,現有的EEG模型在臨床實踐中面臨個體差異大、新患者不斷涌現的挑戰,導致泛化能力不足。為此,本文提出了一種無監督個體持續學習框架(BrainUICL),使模型能在無需標簽的前提下持續適應新個體的同時保持對歷史和未來個體的泛化能力。通過動態自信緩沖區(Dynamic Confident Buffer, DCB)和跨周期對齊(Cross Epoch Alignment, CEA)模塊,平衡模型的可塑性(適應新個體)和穩定性(保持對未見個體的泛化能力)。實驗表明,BrainUICL在睡眠分期、情緒識別和運動想象三種主流EEG任務中均顯著優于現有方法。BrainUICL框架工作流如圖1。
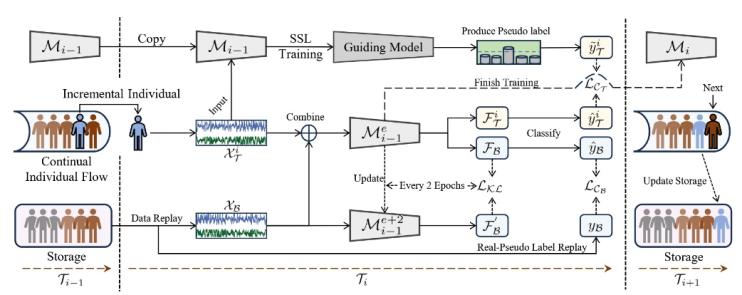
圖1 BrainUICL框架工作流
研究背景
腦電技術因其無創和高時間分辨率的特性,在臨床實踐中扮演著重要角色。然而,現有腦電模型在真實世界應用中表現不佳。主要挑戰在于:
這些問題促使研究者尋求新的解決方案。持續學習(Continual Learning, CL)允許模型從連續的數據流中學習,是解決此問題的理想途徑。然而,CL的核心挑戰在于平衡“穩定性-可塑性(Stability-Plasticity, SP)”困境:既要讓模型有效適應新個體(高的可塑性),又要防止其在適應過程中遺忘已有知識,并保持對所有未見個體的泛化能力(好的穩定性)。
研究方法
本文提出了一種面向腦電圖應用的無監督個體持續學習框架(BrainUICL),旨在解決無監督個體持續學習場景下的上述挑戰。其核心思想是讓模型在逐個適應無標簽的新個體時,不僅表現出良好的適應性(可塑性),還能不斷積累知識,最終成為一個對所有未見個體都具有強大泛化能力的“通用專家”。
實驗所用的數據集均被劃分為預訓練集、增量集和泛化集三個部分,遵循約3:5:2的比例。預訓練集由多個帶真實標簽的個體數據組成,這部分數據用于預訓練,得到一個初始的增量模型;增量集由大量無標簽的、持續到來的新個體數據組成,模型需要在這個數據流上逐個進行無監督的個體域適應,這部分數據主要用于評估模型的可塑性 (Plasticity),即適應新個體的能力;泛化集由另一組帶真實標簽的未見個體數據組成,在模型每完成一輪對增量集中個體的適應后,都會在這個集合上進行測試,以評估其穩定性 (Stability),即對所有未知個體的泛化能力。無監督個體持續學習的過程如圖2所示。
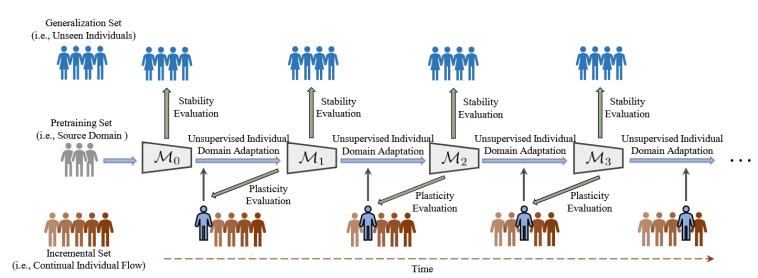
圖2 無監督個體持續學習的過程
BrainUICL框架主要由以下幾個關鍵模塊組成:
(1)SSL訓練生成偽標簽
由于新流入的個體數據沒有標簽,模型首先需要為它們生成高質量的偽標簽。考慮到傳統聚類方法對低信噪比的腦電信號效果不佳,BrainUICL采用對比預測編碼(Contrastive Predictive Coding, CPC)自監督學習算法對一個“指導模型”(拷貝最新的增量模型)進行微調。通過這種方式,指導模型能初步適應新個體的數據分布,從而生成置信度更高、質量更好的偽標簽,用于后續的模型適配訓練。
(2)動態置信緩沖 (DCB)
為防止在持續學習中發生“災難性遺忘”,BrainUICL采用了基于重放(rehearsal-based)的策略。但傳統的樣本回放機制在無監督設定下容易因偽標簽噪聲導致錯誤累積。為此,本文設計了DCB模塊,它包含一個“真實-偽標簽混合回放”策略。其存儲中心分為兩部分:一部分存儲來自源域(預訓練集)的帶真實標簽的樣本,另一部分存儲來自過去個體的高置信度偽標簽樣本。在訓練時,以8:2的比例從真實標簽庫和偽標簽庫中抽取樣本進行混合回放。這種策略既利用真實標簽樣本來校準模型、抑制誤差累積,又通過少量偽標簽樣本來維持樣本多樣性,巧妙地實現了對增量學習過程的“懲罰”與規范。
(3)跨周期對齊 (CEA)
為了防止模型在適應某個特定個體(尤其是異常個體)時發生過擬合,從而損害其長期穩定性和泛化能力,本文提出了CEA模塊。該模塊在模型微調過程中,每隔兩個周期(epoch),就使用KL散度(Kullback-Leibler Divergence)來對齊當前模型狀態與兩個周期前模型狀態的概率分布。通過這種方式,CEA能約束模型的更新方向,防止其在學習新知識時偏離過多,即使遇到異常個體數據也能保持穩定,為后續的持續學習保留了能力空間,最終同時提升了模型的穩定性和可塑性。
(4)模型損失函數
模型的總損失函數由兩部分組成:一部分是針對當前增量個體和動態置信緩沖模塊中的緩沖樣本的交叉熵損失,公式如下:
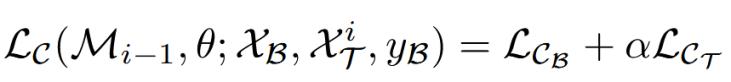
其中:
·: 在動態置信緩沖(DCB)中的樣本上計算的損失;
·:在當前學習的新個體的無標簽數據上,利用生成的偽標簽計算的損失;
·:一個動態調整的超參數;
值得注意的是:會隨著模型見過的個體數量i的增加而逐漸減小,意味著隨著模型學習到的知識越來越豐富,它會逐漸變得更加“謹慎”,減少對新來的、不確定的偽標簽數據的依賴,從而幫助模型最終穩定下來。
另一部分是跨周期對齊CEA模塊計算的KL散度損失。因此模型的總損失函數公式如下:
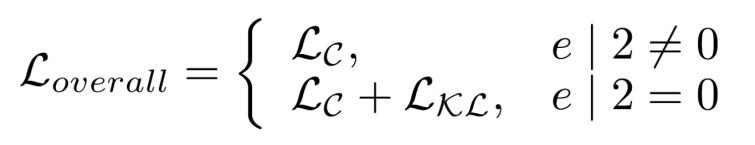
實驗結果
本文在三個主流腦電任務的公共數據集上(睡眠分期ISRUC,情緒識別FACED,運動想象Physionet-MI)對BrainUICL框架進行了全面評估。
總體性能如圖3所示,與初始模型相比,BrainUICL在不斷適應新個體的過程中,不僅顯著提升了對新個體的適應能力(可塑性,例如在ISRUC和FACED數據集上,平均MF1分別提升了13.4%和19.5%),還持續增強了對未見泛化集的性能(穩定性,例如在FACED數據集上,AAA指標從24.0%提升到36.5%),實現了雙贏。

圖3 BrainUICL在三個下游EEG任務上的性能
與多種現有的UDA、CL和UCDA方法性能比較如圖4所示,BrainUICL在三個數據集上都表現出最優的穩定性和魯棒性。
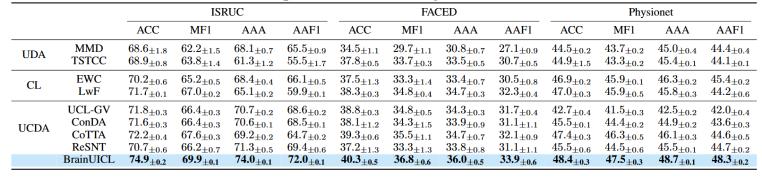
圖4 與現有UDA、CL和UCDA方法的性能比較
結論
本文針對真實世界腦電應用中模型泛化能力不足的痛點,提出了一個新穎的無監督個體持續學習(UICL)范式,并設計了BrainUICL框架以有效應對該范式下的SP困境挑戰。通過創新的動態置信緩沖(DCB)和跨周期對齊(CEA)模塊,BrainUICL能夠在無需人工標注的情況下,持續地從新個體數據中進行學習,不僅能很好地適應新個體,還能不斷提升對所有未見個體的泛化能力,最終成長為一個更魯棒、更通用的腦電解碼模型。該工作為開發實用、高效的臨床腦電智能分析系統提供了新的思路和強大的技術支持。
撰稿人:余淑冰
審稿人:李景聰









