 535
535
 0
0
 2025-04-30
2025-04-30
 2025-04-30
2025-04-30

該論文發表于IEEE Transactions on Information Forensics and Security (中科院一區,IF=6.3),題目為《Attention BLSTM-Based Temporal-Spatial Vein Transformer for Multi-View Finger-Vein Recognition》。重慶工商大學計算機科學與信息工程學院的教授秦華鋒為此文第一作者。重慶大學計算機學院的教授李延濤為此文的通訊作者。
論文鏈接:https://ieeexplore.ieee.org/document/10695117
由于其良好的隱私保護和高度的安全性,指靜脈生物識別技術近年來受到廣泛關注。盡管該領域已取得顯著進展,但大多數現有方法仍主要依賴于從三維靜脈血管投影到二維(2D)圖像上的單視角圖像中提取特征。然而,單視角的識別容易受到手指位置變化(尤其是由于手指旋轉造成的)影響,進而降低識別性能。為了解決這一挑戰,本文提出了一種基于注意力雙向LSTM的時空靜脈Transformer模型——ABLSTM-TSVT,用于多視角指靜脈識別。首先,在LSTM中引入注意力機制,構建了注意力LSTM以提取時序特征。在此基礎上,進一步引入了一個局部注意力模塊,該模塊能夠學習多視角圖像中一個圖像塊(token)與其鄰近圖像塊之間的時間依賴關系,并與注意力LSTM融合形成時序注意力模塊。其次,設計了空間注意力模塊,用于捕捉單張圖像中各圖像塊之間的空間依賴關系。最后,通過融合時序注意力模塊與空間注意力模塊,構建了時空Transformer模型,有效地表征多視角圖像的特征表示。在兩個多視角數據集上的實驗結果表明,本文方法在提升身份識別準確率和減少靜脈分類器驗證誤差方面優于現有先進方法。
研究背景
指靜脈識別仍然是一項具有挑戰性的任務,因為多種因素會導致圖像質量下降,這些因素可大致分為兩類:一是外部因素,如環境光照、溫度變化以及光散射等,這些會在圖像中引入噪聲、不規則陰影,甚至造成靜脈圖案缺失;二是內部因素,如用戶的操作行為,可能會引起圖像的旋轉和平移。在圖像采集過程中,用戶的手指可能沿 X、Y、Z 三個軸發生平移與旋轉:其中,X 和 Y 軸方向的平移會影響圖像中手指區域的位置,Z 軸方向的平移則會改變其尺度;而沿這三個軸的旋轉——即滾轉、俯仰和偏航——會以不同方式影響最終圖像。具體而言,偏航可能使手指在圖像中產生旋轉,俯仰可能導致手指變形從而造成靜脈結構扭曲,尤其值得注意的是,滾轉會改變三維血管結構在二維圖像上的投影角度,尤其在大角度時,不同視角下同一手指采集到的靜脈圖像差異會變得十分顯著,最終導致注冊圖像與測試圖像之間的不匹配,從而影響識別性能。由于大多數用戶對靜脈識別缺乏專業知識,在圖像采集時可能錯誤地放置手指,進一步加劇了采集圖像之間的差異。而無接觸式采集系統則往往帶來更多的變化,包括旋轉、平移和尺度變化。

圖一 手指移動引起的姿勢變化
方法與結果分析
研究方法

圖二 ABLSTM-TSVT框架.(a) ABLSTM-TSVT, (b)時間注意力, (c) BLSTM注意力, (d) LSTM注意力.
基于注意力機制的BLSTM時空靜脈Transformer(即ABLSTM-TSVT)由空間注意力模塊、時間注意力模塊和嵌入層組成,如圖2(a)所示。首先,對多視角指靜脈圖像序列中的每一幅圖像進行卷積處理,將其劃分為 N=196 個圖像塊(patch),每個圖像塊隨后被轉換為一個嵌入向量。接著,這些嵌入向量被送入時間注意力模塊(如圖2(b)所示),以學習多視角圖像之間的時間依賴關系。時間注意力模塊的輸出作為空間注意力模塊的輸入,用于提取圖像內部各圖像塊之間的空間相關性。通過這種交互式的處理流程,模型能夠有效提取并優化圖像序列中的特征,為后續的分類任務提供支持。
A. 序列嵌入
 目前,大多數Transformer模型 ,旨在改進Vision Transformer(ViT),通常會利用其預訓練權重并進行微調,以提升模型的魯棒性。類似地,本文的方法引入了空間注意力模塊,并采用了一個經過預訓練的ViT模型,利用指靜脈圖像對其進行微調。在 ViT 中采用了圖像塊劃分與特征嵌入方案。設X?:? 表示一個多視角指靜脈圖像序列 X?, X?, ..., X?。對于第 t 幅圖像, 在不同像素位置上使用帶有 d = 768 個 p×p(其中 p = 16)的卷積核的卷積操作,步長為 p。這樣,圖像 X? 被轉換為一個由
目前,大多數Transformer模型 ,旨在改進Vision Transformer(ViT),通常會利用其預訓練權重并進行微調,以提升模型的魯棒性。類似地,本文的方法引入了空間注意力模塊,并采用了一個經過預訓練的ViT模型,利用指靜脈圖像對其進行微調。在 ViT 中采用了圖像塊劃分與特征嵌入方案。設X?:? 表示一個多視角指靜脈圖像序列 X?, X?, ..., X?。對于第 t 幅圖像, 在不同像素位置上使用帶有 d = 768 個 p×p(其中 p = 16)的卷積核的卷積操作,步長為 p。這樣,圖像 X? 被轉換為一個由 個token 組成的序列
個token 組成的序列  。在實驗中,所有指靜脈圖像被統一調整為 224×224,因此:
。在實驗中,所有指靜脈圖像被統一調整為 224×224,因此: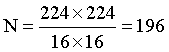 。最終,這些 token 被聚合成一個矩陣
。最終,這些 token 被聚合成一個矩陣  ,從而得到該圖像的嵌入表示。對于整個圖像序列的嵌入,將 T 個矩陣{X?′ | t = 1, ..., T}堆疊起來,得到新的三維張量
,從而得到該圖像的嵌入表示。對于整個圖像序列的嵌入,將 T 個矩陣{X?′ | t = 1, ..., T}堆疊起來,得到新的三維張量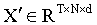 。在 ViT中,一張圖像被劃分為 N 個 patch,每個 patch 被嵌入為一個 token,通過 Transformer 中的自注意力機制學習 patch 之間的空間依賴關系。為了實現魯棒的分類,ViT 在 N 個 token 前連接一個分類 token z?,從而形成 N+1 個 token 輸入到 Transformer 中。Transformer 編碼器的輸出 z? 作為整張圖像的空間特征表示。為了保留在不同時間點采集圖像的空間信息,為每個時間點引入一個時間 token 向量z?:?,維度為 T×1×d,并將其加入到原始嵌入中,得到新矩陣
。在 ViT中,一張圖像被劃分為 N 個 patch,每個 patch 被嵌入為一個 token,通過 Transformer 中的自注意力機制學習 patch 之間的空間依賴關系。為了實現魯棒的分類,ViT 在 N 個 token 前連接一個分類 token z?,從而形成 N+1 個 token 輸入到 Transformer 中。Transformer 編碼器的輸出 z? 作為整張圖像的空間特征表示。為了保留在不同時間點采集圖像的空間信息,為每個時間點引入一個時間 token 向量z?:?,維度為 T×1×d,并將其加入到原始嵌入中,得到新矩陣 。將
。將 輸入到 Transformer 后,編碼器的輸出 z? 表示時間 t 對應圖像的空間信息。
輸入到 Transformer 后,編碼器的輸出 z? 表示時間 t 對應圖像的空間信息。
B. 時間注意力
時間關系信息是多視角分類中的關鍵特征。為了有效地捕捉這種時間信息,引入了一個時間注意力模塊,該模塊由局部時間注意力模塊和注意力雙向 LSTM(BLSTM)組成。
1)局部時間注意力
論文中提出一個局部時間注意力模塊,用于建模多視角圖像中相鄰 patch 的 token 之間的關系。將分類 token 從 中去除,得到
中去除,得到 。為了捕捉時間特征表示,在多視角圖像的 token 之間設計了自注意力機制。來自第 t 幅圖像的 token 表示為
。為了捕捉時間特征表示,在多視角圖像的 token 之間設計了自注意力機制。來自第 t 幅圖像的 token 表示為  ,它被劃分為由其相鄰 patch 中的 L×L 個 token 組成的窗口。這些窗口不重疊,因此圖像 X′? 被劃分為
,它被劃分為由其相鄰 patch 中的 L×L 個 token 組成的窗口。這些窗口不重疊,因此圖像 X′? 被劃分為 個窗口,并重新組織為矩陣
個窗口,并重新組織為矩陣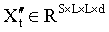 。對于一個指靜脈的所有多視角圖像,共有 T 個此類矩陣,它們被打包為矩陣
。對于一個指靜脈的所有多視角圖像,共有 T 個此類矩陣,它們被打包為矩陣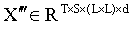 。為了學習某個窗口內的時間信息,取第 s 個窗口在不同視角下的集合,構成矩陣
。為了學習某個窗口內的時間信息,取第 s 個窗口在不同視角下的集合,構成矩陣 ,其中包含 T × 1 × (L × L) 個 token。通過這些 token 的自注意力計算時間依賴關系。令
,其中包含 T × 1 × (L × L) 個 token。通過這些 token 的自注意力計算時間依賴關系。令  (其中 i = 1, ..., T × (L × L)表示第 s 個窗口中、第 T 幅圖像內的第 i 個 token。該 token 通過一個線性層被映射為三個向量,分別是查詢向量
(其中 i = 1, ..., T × (L × L)表示第 s 個窗口中、第 T 幅圖像內的第 i 個 token。該 token 通過一個線性層被映射為三個向量,分別是查詢向量 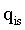 、鍵向量
、鍵向量  和數值向量
和數值向量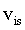 。論文中將所有查詢向量
。論文中將所有查詢向量  (i = 1, ..., T × (L × L)聚合成一個矩陣 Q?,同樣地,鍵和數值向量分別聚合為矩陣 K? 和 V?。第 s 個窗口中所有 token 的自注意力隨后通過公式 (1) 進行計算:
(i = 1, ..., T × (L × L)聚合成一個矩陣 Q?,同樣地,鍵和數值向量分別聚合為矩陣 K? 和 V?。第 s 個窗口中所有 token 的自注意力隨后通過公式 (1) 進行計算:
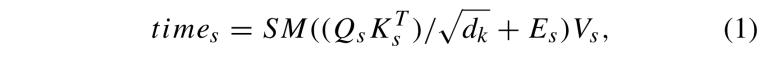
其中,E? 表示相對位置偏置,SM(·) 是對相似度矩陣 A? = Q?K?? 的每一行應用的 Softmax 操作,d? 表示歸一化參數。通過組合 M 個單頭注意力機制,計算多頭注意力,來增強特征表示能力。如公式 (2) 所示:
![]()
其中, ,m (m = 1, 2, …, M) 表示多頭注意力中的第 m 個頭。類似地,在 s (s = 1, 2, …, S) 個窗口中計算多頭注意力 timeMSAT?,并將其組合成一個矩陣
,m (m = 1, 2, …, M) 表示多頭注意力中的第 m 個頭。類似地,在 s (s = 1, 2, …, S) 個窗口中計算多頭注意力 timeMSAT?,并將其組合成一個矩陣 。
。
2)注意力 BLSTM
論文中在 LSTM 架構中引入了注意力機制,構建了注意力 LSTM(見圖 2(d))。進一步地,將其擴展為雙向 LSTM(BLSTM)網絡(見圖 2(c)),以從圖像的左右兩個方向提取信息。
從變換后的表示 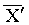 中,論文提取出類別標記
中,論文提取出類別標記 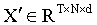 。每張圖像的嵌入向量被視為一個 token,其中 X′? 表示第 t 張圖像的第 t 個 token,
。每張圖像的嵌入向量被視為一個 token,其中 X′? 表示第 t 張圖像的第 t 個 token, 表示前一時刻的隱藏狀態。通過一個線性變換層,將
表示前一時刻的隱藏狀態。通過一個線性變換層,將 映射為三個向量:
映射為三個向量: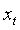 的查詢向量 Q?、鍵向量 K? 和值向量 V?。同樣地,對前一隱藏狀態
的查詢向量 Q?、鍵向量 K? 和值向量 V?。同樣地,對前一隱藏狀態 計算查詢向量 Q?、鍵向量 K? 和值向量 V?。輸入向量
計算查詢向量 Q?、鍵向量 K? 和值向量 V?。輸入向量  的自注意力機制按公式(3)計算:
的自注意力機制按公式(3)計算:

采用這種方法,通過公式(4)、公式(5)和公式(6)分別獲得隱藏狀態 的自注意力機制以及
的自注意力機制以及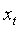 與
與 之間的交叉注意力機制。
之間的交叉注意力機制。
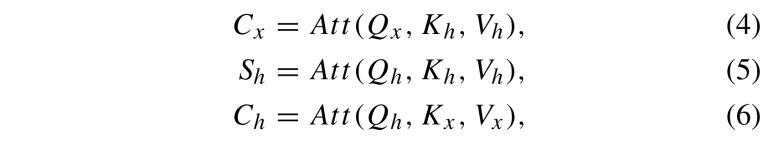
其中,C? 和 C? 分別表示輸入向量 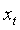 與前一隱藏狀態
與前一隱藏狀態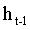 之間的交叉注意力機制,S? 表示隱藏狀態的自注意力機制。
之間的交叉注意力機制,S? 表示隱藏狀態的自注意力機制。
LSTM 架構包含四個模塊:遺忘門、輸入門、記憶單元和輸出門。其中,遺忘門 決定從記憶單元中舍棄哪些信息。該決策由一個 Sigmoid 激活函數控制,如公式(7)所示:
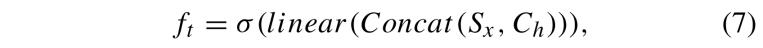
其中,σ 表示 Sigmoid 函數,linear 表示線性映射函數,Concat 表示向量拼接操作。輸入門 負責處理當前輸入,如公式 (8) 和公式 (9) 所示:

記憶單元被設計用于緩解梯度消失問題,從而有助于模型的訓練,特別適用于包含長序列的數據集。記憶單元的輸出由公式 (10) 給出:

其中,⊙ 表示 Hadamard(元素級)乘法運算符。
與前兩個門控機制類似,輸出門通過公式 (12) 計算:

BLSTM 是 RNN 的一種變體,增強了標準 LSTM 在處理長期依賴關系方面的能力。為了進一步提升性能,論文中提出了注意力 BLSTM(Attention BLSTM),該結構在前向和后向兩個方向中引入注意力機制,從而實現信息的同步提取,如圖 2(c) 所示。在 Forward 層中,注意力 LSTM 按順序從第 1 個 token 處理到第 T 個 token,逐步獲取前向隱藏層的輸出。相反,在 Backward 過程中,注意力 LSTM 按相反順序從第 T 個 token 處理到第 1 個 token,逐步獲取后向隱藏層的輸出。六個權重 V、V′、U、U′、Z 和 Z′ 被迭代使用,以通過公式 (13)、(14) 和 (15) 融合前向和后向層的輸出。

輸出  (t = 1, 2 …, T)被組織成一個矩陣
(t = 1, 2 …, T)被組織成一個矩陣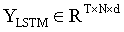 。如圖 2(b) 所示,隨后將
。如圖 2(b) 所示,隨后將  與
與  結合,通過公式 (16) 得到 Y。
結合,通過公式 (16) 得到 Y。

最終,如圖 2(b) 所示,使用具有兩層全連接層的多層感知機(MLP)進行魯棒的特征提取。論文采用兩次線性變換,通過公式 (17) 將得到的映射 Y 轉換:
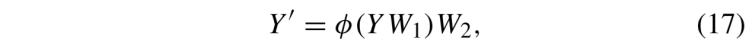
其中,φ(·) 表示 ReLU 激活函數。
C. 空間注意力
為了提取空間信息,在每張圖像的 N 個空間 token 上實現了自注意力機制。矩陣 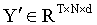 被重新調整為
被重新調整為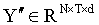 ,其中 Y?′′ 表示包含 N 個 token 的矩陣,這些 token 對應于第 t 張圖像中的補丁。對于第 t 張圖像中這 N 個 token 的空間自注意力,通過公式 (18) 計算:
,其中 Y?′′ 表示包含 N 個 token 的矩陣,這些 token 對應于第 t 張圖像中的補丁。對于第 t 張圖像中這 N 個 token 的空間自注意力,通過公式 (18) 計算:
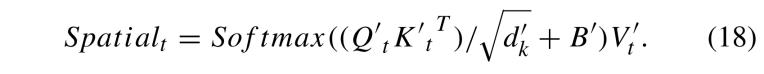
多頭注意力機制在不同的位置使用公式 (19) 實現:

其中, (m = 1, 2, . . . , M)。通過這種方式,計算所有圖像中的多頭注意力 SpatialM SAT? (t = 1, 2, . . . , T),然后將其合并成一個矩陣
(m = 1, 2, . . . , M)。通過這種方式,計算所有圖像中的多頭注意力 SpatialM SAT? (t = 1, 2, . . . , T),然后將其合并成一個矩陣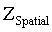 。最后,將 L 個時空模塊層疊在一起,構建 ABLSM-TSVT(如圖 2(a) 所示),從而促進從多視角圖像中提取魯棒特征。
。最后,將 L 個時空模塊層疊在一起,構建 ABLSM-TSVT(如圖 2(a) 所示),從而促進從多視角圖像中提取魯棒特征。
實驗結果
ABLSTM-TSVT在全視圖靜脈數據集CTBU(包含3視角、6視角和9視角)和多模態數據集LFMB-3DFB(包含3視角與6視角)進行了實驗
對比實驗:
閉集場景中的識別性能
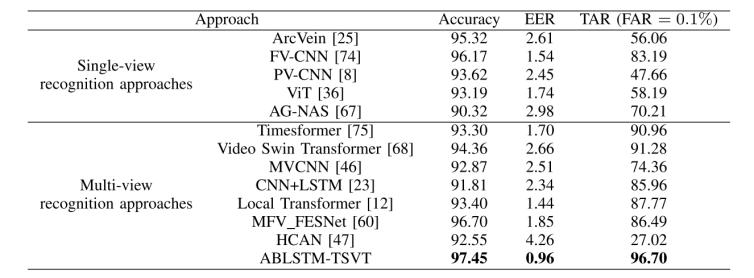
為了評估所提方法的有效性,論文中將 ABLSTM-TSVT 與代表性的 2D 單視角識別方法,以及 3D 多視角識別方法進行比較。常用的均衡誤差率(EER)用于評估性能,它是虛假接受率(FAR)等于虛假拒絕率(FRR)時的點。此外,采用了TAR@FAR = 0.1%,其中TAR = 正確接受的合法用戶數 / 所有合法用戶數,FAR = 錯誤接受的非法用戶數 / 所有非法用戶數,TAR@FAR = 0.1%是指FAR 限制在 0.1% 的時候,系統對合法用戶的接受率是多少。表 一、二、三、四 和 五 展示了在兩個數據集上各種方法的識別準確率。

表一 數據集CTBU的三視圖子集上各方法的識別準確率(%)
表二 數據集CTBU的六視圖子集上各方法的識別準確率(%)

表三 數據集CTBU的九視圖子集上各方法的識別準確率(%)

表四 數據集LFMB-3DFB的三視圖子集上各方法的識別準確率(%)

表五 數據集LFMB-3DFB的六視圖子集上各方法的識別準確率(%)
具體而言,對于數據集 CTBU,所提出方法達到了 97.55% 的識別準確率和 0.96% 的 EER;對于數據集 LFMB-3DFB,則分別達到了 98.06% 的識別準確率和 0.54% 的 EER。特別地,在 FAR = 0.1% 時,所提出方法在數據集 CTBU上達到了 97.77% 的 TAR,在數據集 LFMB-3DFB上達到了 98.71% 的 TAR。
開集場景中的識別性能
實驗結果如表六所示,表明所提出方法在兩個數據集上都保持了高識別性能,即使測試集中包含了來自額外類別的樣本。該方法能夠有效識別并拒絕冒名頂替者,從而展示了所提出的指靜脈識別系統在實際應用中的有效性。此外,表七中的驗證結果表明,即使測試集僅包含新類別,該方法仍然能夠取得令人滿意的驗證性能。這些結果表明,該方法非常適合實際的驗證場景。

表六 開集場景下的識別準確(%)(FAR = 1%)

表七 開集場景下的驗證錯誤率(%)
消融實驗:
首先,論文中使用標準的自注意力模塊來捕捉空間依賴性,該方案作為基線(baseline)。隨后,引入鄰域時間注意力來學習多視角圖像間的時間依賴性,該方案被記作 (baseline)+ 局部時間注意力。類似地,將局部時間注意力替換為注意力BLSTM模塊,此方案記作 (baseline)+ BLSTM注意力。最后,同時結合局部時間注意力模塊與注意力BLSTM模塊提取時間信息,同時保留標準的空間自注意力機制,用于空間特征學習,構成 ABLSTM-TSVT模型(baseline+BLSTM注意力 + 局部時間注意力)。
各種方法在兩個數據集上的識別結果展示在表八、九、十、十一與十二中。實驗結果表明,引入的局部時間注意力模塊與注意力BLSTM模塊能顯著提升識別性能。

表八 各方法在數據集CTBU三視角子集上的識別準確率(%)

表九 各方法在數據集CTBU六視角子集上的識別準確率(%)

表十 各方法在數據集CTBU九視角子集上的識別準確率(%)

表十一 各方法在數據集LFMB-3DFB三視角子集上的識別準確率(%)

表十二 各方法在數據集LFMB-3DFB六視角子集上的識別準確率(%)
結論
本文提出了一種基于注意力雙向LSTM的時空靜脈Transformer(ABLSTM-TSVT),用于多視角靜脈圖像識別。ABLSTM-TSVT由多個時空模塊組成,每個模塊包括一個時間模塊和一個空間模塊。時間模塊能夠有效學習序列中多視角指靜脈圖像之間的魯棒時間特征依賴關系,而空間模塊則用于捕捉圖像內部各個圖像塊之間的空間依賴。在兩個多視角靜脈數據集上的綜合實驗結果表明,ABLSTM-TSVT優于當前的2D/3D靜脈識別方法,在多視角三維指靜脈識別任務中實現了最高的識別準確率。多視角三維指靜脈識別的研究熱度不斷提升,原因在于其能夠提供更具區分性的信息,并緩解由手指滾動帶來的圖像不匹配問題。
撰稿人:張坤鵬
審稿人:黃俊端









