







ICDE 2025 | PKU-DAIR實驗室論文被ICDE 2025
錄用兩篇
ICDE(International Conference on Data Engineering )是數據庫領域影響力最高的國際學術會議之一,也是CCF推薦的A類國際學術會議之一。第41屆IEEE國際數據工程大會(ICDE)將于2025年5月19日-23日在中國香港舉行。
PKU-DAIR實驗室論文《 Towards Scalable and Efficient Graph Structure Learning 》和《Training-free Heterogeneous Graph Condensation via Data Selection》被數據庫領域頂級會議ICDE 2025錄用論文兩篇。
一、面向可擴展且高效的圖結構學習
作者:Siqi Shen, Wentao Zhang, Chengshuo Du , Chong Chen, Fangcheng Fu, Yingxia Shao, Bin Cui
1. 引言
圖結構學習(Graph Structure Learning,GSL)是一類提升圖結構質量和圖神經網絡(GNN)下游任務表現的方法。然而,在實際應用中,GSL通常面臨以下兩大挑戰:
(1)可擴展性不足
GSL方法的擴展性受限于高計算復雜度和架構耦合。許多方法的運算復雜度高達O(N^2)(N為節點數),導致執行時間長、內存消耗大,尤其在大規模圖上表現明顯。此外,結構優化模塊與特定GNN架構緊密耦合,難以與如SGC、SIGN等可擴展GNN兼容,進一步限制了其適用性。
(2)效率低下
現有的GSL方法效率偏低,實驗結果充分證明了這一點。我們選用三個常用數據集(Cora、Citeseer和Pubmed),并選取了NodeFormer、CoGSL和SLAPS三個代表性GSL基線模型,記錄了它們在上述數據集上的端到端訓練時間。實驗結果(下圖)顯示,即便在小規模圖數據上,這些GSL方法的處理時間也顯著高于普通GNN的訓練時間,并且隨著圖規模的增大,執行時間呈現快速增長趨勢。同時,圖結構優化與圖學習模塊的強耦合性要求每次更換GNN架構時都需重新訓練,進一步增加計算開銷,降低靈活性。
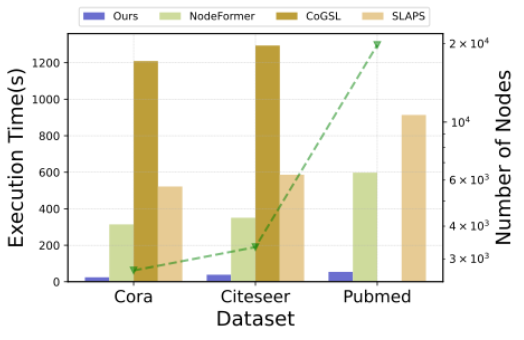 圖1. 在三個數據集上的不同執行時間
圖1. 在三個數據集上的不同執行時間
這些挑戰凸顯了在大規模圖學習任務中,提升GSL方法可擴展性和效率的緊迫性。
2. 方法
針對現有GSL方法在可擴展性和效率上的不足,我們提出了一種新方法,稱為基于隨機游走的圖結構學習(簡稱RWGSL)。
為了解決可擴展性問題,我們引入了鄰域采樣和隨機游走策略,避免了對圖中所有節點對進行大規模計算的需求,從根本上降低了計算復雜度,顯著緩解了高復雜度帶來的計算資源消耗。
為了解決效率問題,我們將圖結構優化模塊與圖學習模塊解耦,并將優化過程前置到數據預處理階段。此設計具有兩方面優勢:一方面,可以利用多進程并行技術加速圖結構優化過程;另一方面,優化后的圖結構與具體的GNN架構無關,從而具備更高的通用性和靈活性。
在圖結構優化模塊中,我們綜合考慮圖拓撲結構和監督信號等多方面因素,計算節點間的多維度相似性,以進一步提升方法的有效性,確保優化后的圖結構能夠更好地支持下游任務的性能表現。下圖是我們的方法框架。
 圖2. RWGSL框架
圖2. RWGSL框架
3. 實驗結果
下表展示了RWGSL在三個中等規模數據集上的節點分類結果。為清晰起見,我們標注了每種基礎GNN模型在使用優化后的圖結構作為輸入時所帶來的準確率提升。此外,我們將每個數據集上的最佳結果用加粗表示,次優結果用下劃線標注。

表1. 中等規模數據集上的節點分類結果
實驗結果表明,與原始圖相比,使用RWGSL處理后的圖能夠顯著提升分類準確率。具體而言,RWGSL將基礎GCN的分類準確率在Cora數據集上提升了3.0%,在Citeseer數據集上提升了2.6%,在Pubmed數據集上提升了2.1%。值得注意的是,當RWGSL與GCN結合時,其表現可與其他先進的圖結構學習方法相媲美。此外,這些結果進一步驗證了RWGSL的強泛化能力:優化后的單一圖結構能夠在所有基線模型中一致提升性能。
我們還在一個大規模數據集Ogbn-Products上進行了實驗,其結果展示在下表的左兩列中。

表2. 大規模數據集上的實驗結果
該表清楚地表明,大多數圖結構學習方法在處理大規模圖時面臨顯著挑戰。雖然NodeFormer在一定程度上展現了處理大規模圖的能力,但其表現仍未達到最優。相比之下,當與可擴展的GNN結合時,我們的方法RWGSL能夠有效優化大規模圖的拓撲結構,展現出令人期待的結果。具體而言,RWGSL將SGC的分類準確率提升了4.0%,SIGN提升了1.7%,GraphSAGE提升了1.3%,GraphSAINT提升了1.6%。這些結果表明,RWGSL在處理大規模圖結構優化方面具有顯著優勢,能夠有效提升可擴展GNN的性能。
4. 總結
通過對圖結構學習方法的調研和實踐,我們發現現有工作普遍面臨兩個關鍵挑戰:可擴展性有限和效率低下。具體而言,這些方法在處理大規模圖數據集時常常遭遇運行時間過長和內存消耗過大的問題。為了解決這些局限性,我們提出了一種無參數、非參數學習型的圖結構學習方法——RWGSL。
RWGSL通過在數據預處理階段優化圖結構并利用采樣策略縮小搜索空間,顯著降低了計算復雜度。其優化后的圖結構為圖學習模型提供了更高質量的輸入,在多種圖類型上均實現了性能的持續提升。
我們在多個數據集上進行了廣泛實驗,驗證了RWGSL的有效性和可擴展性,為高效圖學習技術的進一步探索與發展提供了新的方向和動力。
二、通過數據選擇實現無需訓練的異構圖壓縮
作者:Yuxuan Liang, Wentao Zhang, Xinyi Gao, Ling Yang, Chong Chen, Hongzhi Yin, Yunhai Tong, Bin Cui
論文鏈接:https://arxiv.org/abs/2412.16250
1. 引言
最近,圖壓縮(GC)已被提出作為密集計算問題的一種有前途的解決方案。圖壓縮旨在通過學習合成圖結構和節點屬性來壓縮大型原始圖。作為關鍵設計,GC 利用中繼模型連接原始圖和合成圖,方便兩個圖的比較和壓縮優化。遵循 GCond 的梯度匹配范式,HGCond是第一個提出的用于壓縮異構圖的工作。與 GC 不同,它使用聚類信息進行超節點初始化,并采用正交參數序列(OPS)策略來探索參數。雖然這種方法可以壓縮異構圖,但它仍然存在兩個局限性:
(1)低性能: 考慮到模型復雜性導致的過擬合問題,HGCond 被迫僅使用最簡單的異構圖模型作為圖壓縮的中繼模型,其壓縮精度與最先進的 (SOTA) HGNN之間存在很大差距。即使使用先進的 HGNN 作為中繼模型,性能也會變差。此外,復雜的優化問題使得 HGCond 的性能隨著壓縮圖的大小增加而下降或變平。同時,HGCond還存在泛化性差的問題。
(2)效率低: 遵循同構圖壓縮方法 GCond 的范式,HGCond 需要雙層優化和嵌套循環來壓縮異構圖。這種復雜的壓縮過程計算量大且耗時。舉例來說,在128 個 epoch下大約需要 1 小時(在單個 TITAN RTX GPU 上運行)才能將大規模數據集 AMiner壓縮到 1%。
為了解決上述兩個挑戰,本文提出了一種新的無需訓練的異構圖壓縮方法,稱為 FreeHGC,用于從原始圖結構中選擇和合成高質量圖,而無需模型訓練過程。與傳統的異構圖壓縮不同,傳統的異構圖壓縮通過迭代訓練中繼模型來優化合成圖和參數,如圖 1 所示,我們提出的 FreeHGC 與模型無關,僅在預處理階段壓縮圖。圖 1 還從四個關鍵標準突出了 FreeHGC 與 HGCond 相比的優勢:有效性、效率、靈活的壓縮率和泛化。
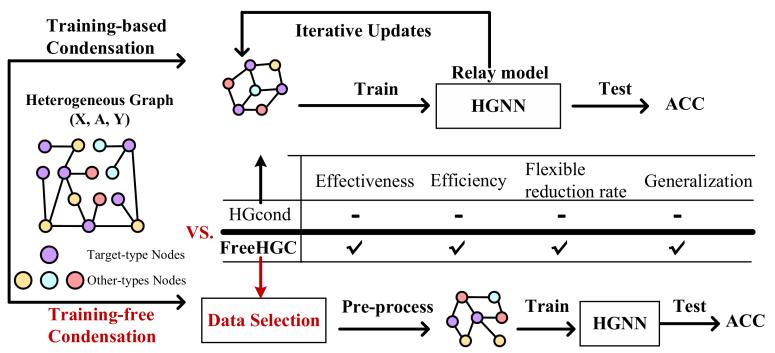
圖1. 現有異構圖壓縮方法與FreeHGC 的對比
2. 方法
FreeHGC執行流程。我們提出第一種無需訓練的異構圖壓縮方法——FreeHGC。如圖2所示,我們的方法分為兩個部分:壓縮目標類型節點和壓縮其他類型節點。第一個部分使用感受野最大化函數和元路徑相似度最小化函數,基于圖結構的直接影響和元路徑之間的間接影響來計算節點的重要性。然后,FreeHGC將這兩個函數結合起來作為統一的數據選擇標準來選擇高質量數據,在確保每個節點沿著不同的元路徑捕獲更豐富的圖結構信息的同時,最大化節點的影響力。第二個部分使用鄰居重要性最大化函數來選擇重要的父類型節點,并使用信息損失最小化函數來合成葉類型節點。重復上述過程,直到獲得壓縮圖。
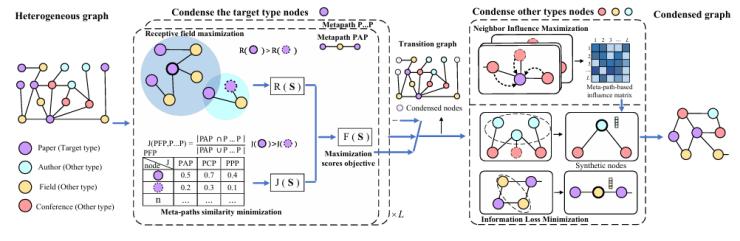
圖2. FreeHGC架構
3. 實驗結果
實驗主要包含以下五個方面:(1)有效性;(2) 可擴展性;(3) 泛化性;(4) 壓縮數據分析;(5)消融實驗。這里選取具有代表性的有效性實驗和可擴展性實驗,其余實驗可參考論文。
(1)與最先進的圖壓縮方法進行端到端比較:如表1所示,在大多數壓縮率設置下,FreeHGC 的表現均優于所有基線方法。

表2. 節點分類預測任務的實驗結果
(2)可擴展性:如表2所示,FreeHGC在不同的壓縮率下表現最佳,且準確度逐漸提高。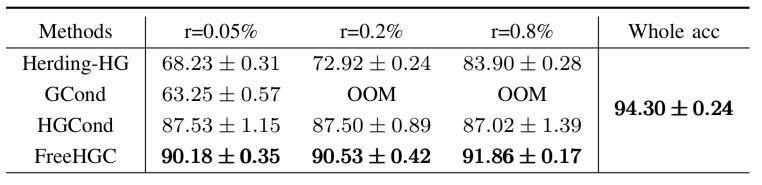
表3. 大規模數據集上的實驗結果
4. 總結
本文提出了一種新的無需訓練的異構圖壓縮方法——FreeHGC。其目標是從原始大圖中選取并合成高質量節點,然后將其壓縮為無需訓練的小圖。節點分類任務上的實驗結果表明,FreeHGC 可以在保持令人滿意的性能的同時顯著減小圖的大小,并且具有靈活壓縮率的優勢。此外,實驗結果還表明我們的方法具有良好的泛化性和可擴展性。
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文100余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0