








PKU-DAIR實(shí)驗(yàn)室兩項(xiàng)成果被SIGMOD 2025錄用
SIGMOD是計(jì)算機(jī)科學(xué)領(lǐng)域的頂級國際學(xué)術(shù)會(huì)議之一,專注于數(shù)據(jù)庫系統(tǒng)和數(shù)據(jù)管理技術(shù)的研究。作為中國計(jì)算機(jī)學(xué)會(huì)(CCF)推薦的A類會(huì)議,SIGMOD與VLDB、ICDE并稱為數(shù)據(jù)庫領(lǐng)域的三大頂會(huì)。PKU-DAIR實(shí)驗(yàn)室《Malleus: Straggler-Resilient Hybrid Parallel Training of Large-scale Models via Malleable Data and Model Parallelization》和《PQCache: Product Quantization-based KVCache for Long Context LLM Inference》兩篇論文在SIGMOD第四輪評審中被成功錄用。
1. Malleus: Straggler-Resilient Hybrid Parallel Training of Large-scale Models via Malleable Data and Model Parallelization
作者:Haoyang Li, Fangcheng Fu, Hao Ge, Sheng Lin, Xuanyu Wang, Jiawen Niu, Yujie Wang, Hailin Zhang, Xiaonan Nie, Bin Cui
論文鏈接:https://arxiv.org/abs/2410.13333
Github鏈接:https://github.com/PKU-DAIR/Hetu
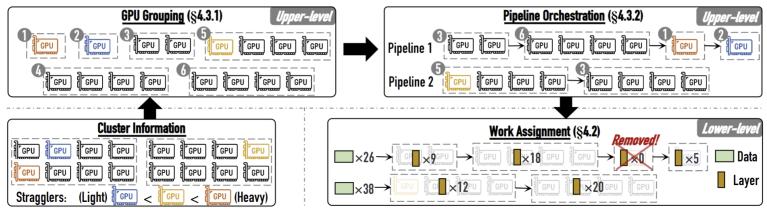
圖1. Malleus概覽
在大規(guī)模模型訓(xùn)練過程中,個(gè)別GPU或機(jī)器出現(xiàn)性能波動(dòng)(稱為“掉隊(duì)者”,straggler)會(huì)顯著影響整個(gè)集群的性能。這些straggler的產(chǎn)生可能由多種因素引起,例如GPU過熱、后臺(tái)進(jìn)程干擾、資源競爭或未知故障等。目前,常見的解決方案是將掉隊(duì)者所在的整個(gè)數(shù)據(jù)并行組(replica)移除,但這種做法會(huì)導(dǎo)致大量正常節(jié)點(diǎn)無法得到充分利用。我們意識到,一方面,性能下降的straggler仍然可以被有效利用;另一方面,對于性能嚴(yán)重下降的straggler,僅需移除其自身,而不必移除整個(gè)replica。
為此,我們通過引入四個(gè)維度的異構(gòu)(data、layer、device和stage),設(shè)計(jì)了一個(gè)能夠感知straggler并細(xì)粒度調(diào)整異構(gòu)訓(xùn)練策略的系統(tǒng)Malleus。實(shí)驗(yàn)表明,在多種straggler場景下,與Megatron-LM和DeepSpeed相比,我們的系統(tǒng)能夠?qū)崿F(xiàn)2.63-5.28倍的加速比,并具備更快的恢復(fù)速度。
2. PQCache: Product Quantization-based KVCache for Long Context LLM Inference
作者:Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, Bin Cui
論文鏈接:https://arxiv.org/abs/2407.12820
Github鏈接:https://github.com/HugoZHL/PQCache

圖2. PQCache概覽
近年來,大型語言模型 (LLM) 的上下文窗口不斷擴(kuò)展,從最初的幾千token發(fā)展到如今的百萬token級別。然而,GPU顯存的限制使得LLM推理過程中token的中間表示——鍵值緩存KVCache成為主要的內(nèi)存瓶頸,嚴(yán)重制約了模型的實(shí)際應(yīng)用。現(xiàn)有方法嘗試通過選擇性保留部分tokens的KVCache來緩解這一問題,但往往面臨模型質(zhì)量下降或服務(wù)延遲增加的困境。
借鑒數(shù)據(jù)管理領(lǐng)域的信息檢索技術(shù),我們創(chuàng)新性地將KVCache的管理問題轉(zhuǎn)化為嵌入檢索任務(wù)。我們提出了PQCache方法,基于乘積量化(PQ)來管理KVCache,在確保低服務(wù)延遲的同時(shí)保持模型質(zhì)量。在預(yù)填充階段,我們將PQ應(yīng)用于每個(gè)LLM層中自注意力頭的所有token的鍵。在自回歸解碼階段,我們使用PQ編碼和聚類中心來近似檢索重要的token,然后獲取相應(yīng)的鍵值對進(jìn)行自注意計(jì)算。通過精心設(shè)計(jì)重疊和緩存,我們最大限度地減少了兩個(gè)階段的任何額外計(jì)算和通信開銷。大量實(shí)驗(yàn)表明,PQCache 兼具有效性和效率,在多個(gè)長文本benchmark和任務(wù)上表現(xiàn)優(yōu)異,并且在預(yù)填充和解碼階段都具有較低的系統(tǒng)延遲。
實(shí)驗(yàn)室簡介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),長期從事數(shù)據(jù)庫系統(tǒng)、大數(shù)據(jù)管理與分析、人工智能等領(lǐng)域的前沿研究,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,已在國際頂級學(xué)術(shù)會(huì)議和期刊發(fā)表學(xué)術(shù)論文200余篇,發(fā)布多個(gè)開源項(xiàng)目。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博、ACM中國優(yōu)博、北大優(yōu)博、微軟學(xué)者、蘋果獎(jiǎng)學(xué)金、谷歌獎(jiǎng)學(xué)金等榮譽(yù)。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,解決實(shí)際問題,進(jìn)行科研成果的轉(zhuǎn)化落地。
載")

評論 0