







PKU-DAIR實驗室兩項成果被ASPLOS 2025錄用
ASPLOS (ACM International Conference on Architectural Support for Programming Languages and Operating Systems) 是計算機科學領域頂級的國際學術會議之一,專注于計算機體系結構、編程語言與操作系統等領域。ASPLOS是計算機系統領域最具影響力的會議之一,屬于計算機科學領域的A類會議(中國計算機學會CCF評定的A類會議),錄用的難度相對較大,接受率通常較低,約為15%到20%之間,每年接收的論文約為100~150篇。PKU-DAIR實驗室《Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling》和《FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism》兩篇論文被ASPLOS 2025錄用!論文核心作者包括北大PKU-DAIR實驗室四年級博士生王馭捷、三年級碩士生竺沈涵、北航本科四年級科研實習生王士舉等。歡迎對分布式深度學習系統、高效大模型框架感興趣的學界業界人士關注我們的工作!
論文接收信息如下:
1. Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
作者:Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
論文鏈接:https://arxiv.org/abs/2409.03365
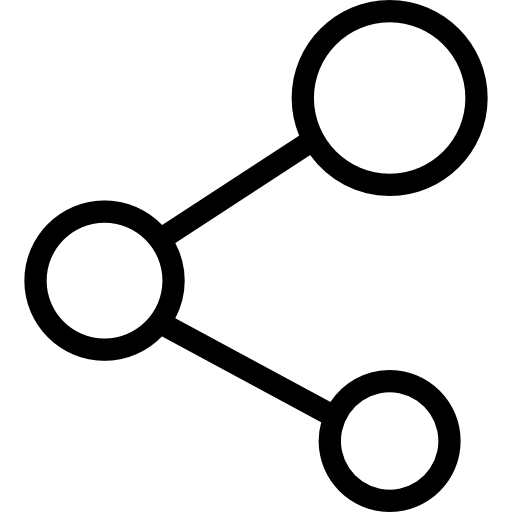
近期最先進的大規模基座模型具備了同時理解和處理多個任務、多種數據模態的強大能力,例如語言任務、圖像任務、視頻任務、語音任務等。這類模型通常由一個統一的基礎模型結構和多個專門化的模型組件組成,其模型結構復雜,圖1展示了多任務多模態大模型的復雜結構。現有的大模型訓練系統均主要針對單一任務、單一模態的模型而設計,而如此復雜的多任務多模態大模型會對高效訓練系統的設計帶來巨大挑戰,一方面其復雜模型結構和多任務多模態特性使其存在嚴重的負載異構性,導致現有系統訓練這類模型容易造成資源浪費和低效,另一方面復雜的模型結構同時也帶來復雜的執行依賴,而現有系統無法高效處理這種依賴。
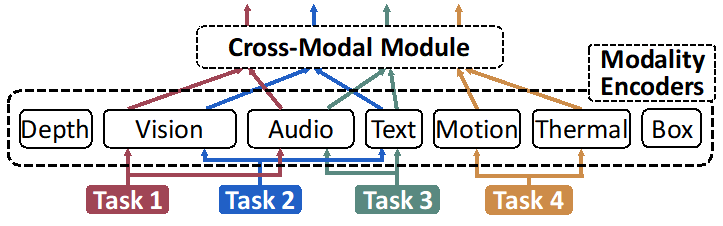
圖1:多任務多模態大模型的復雜模型結構

圖2:現有系統訓練多任務多模態大模型的資源低效和浪費
為此,本工作設計了一個全新的訓練系統——Spindle,旨在通過波面調度(Wavefront Scheduling)的方法實現多任務多模態大模型高效分布式訓練。Spindle的核心思想是將負載異構和執行依賴的復雜模型分解為多個順序執行的波(Wave)。具體而言,波(Wave)是Spindle中最小粒度的執行調度單位,在每個波內,集群中會存在多個算子并行執行,這些算子各自占據一部分集群資源并具有相近的執行時間開銷,一個波代表著一種集群資源分配模式。Spindle將復雜的模型執行分解為多個波,并順序地解決聯合優化問題,包括異構負載感知的并行化和依賴驅動的執行調度,從而實現多任務大模型的高效訓練。

圖3:Spindle系統框架概覽

圖4:Spindle基于波面調度的訓練執行規劃示意圖
圖3展示了Spindle的系統框架架構,其由執行規劃器(Execution Planner)和訓練框架(Training Framework)組成,執行規劃器分為五個系統組件,包括:圖收縮組件(Graph Contraction)負責對龐大的計算圖進行收縮簡化,可擴展性估計器(Scalability Estimator)負責對負載異構的算子進行執行開銷和可擴展性的準確估計,資源分配器(Resource Allocator)負責對算子分配合適的計算資源量,波面調度器(Wavefront Scheduler)負責將算子組織成多個順序執行的波并生成波面調度方案,設備放置器(Device Placement)負責將各個算子放置到GPU設備上并生成最終的執行規劃,并交由運行時引擎(Runtime Engine)進行高效的多任務大模型訓練。圖4給出了一個Spindle基于波面調度的訓練執行規劃的示意圖,其包含了六個順序執行的波。

圖5:Spindle相比于現有系統的端到端性能對比實驗
我們實現并構建了該系統,并在多種多任務多模態模型上進行了評估。圖5展示了Spindle相比于現有系統的端到端性能對比實驗,實驗結果表明,Spindle在性能和效率方面優于現有的訓練系統(例如Megatron-LM和DeepSpeed),加速比最高可達71%。
2. FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
作者:Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
論文鏈接:https://arxiv.org/abs/2412.01523
代碼鏈接:https://github.com/PKU-DAIR/Hetu-Galvatron
隨著大語言模型(LLMs)的快速發展和取得的巨大成就,擴展其上下文長度(即最大支持的序列長度)成為了一個迫切需求。為支持LLM的長上下文訓練,序列并行作為關鍵技術應運而生,它將每個輸入序列切分并分散到多個設備上,并通過必要的通信來處理這些序列。然而,現有的序列并行方法假設輸入序列是同質的(即所有序列長度一致),并采用單一靜態并行策略,這在實際應用中是低效的。
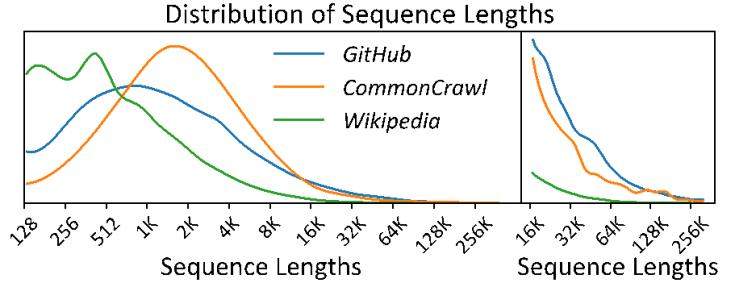
圖1:大語言模型訓練語料庫中序列長度的長尾分布
圖2:不同序列并行度下不同序列的訓練時間和通信時間占比
具體而言,在真實世界的大語言模型訓練語料庫中,序列長度表現出顯著的差異,通常呈長尾分布(如圖1所示),短序列占絕大部分,而長序列較少,這種差異性導致訓練負載的異構性。長序列需要更大的并行度來分攤顯存開銷,但這會受到跨機通信帶寬的限制,導致較高的額外通信開銷(如圖2展示)。相對而言,低并行度策略更為高效。然而,現有同構系統在訓練中只能使用單一靜態的策略,這使得短序列也不得不采用低效的高并行度策略,而短序列又占據了訓練數據集的絕大部分,這導致現有同構系統處理真實異構數據時效率很低。

圖3:FlexSP異構自適應序列并行的例子
為了解決這一問題,我們首次提出了一個基于異構理念設計的訓練系統FlexSP,其使用異質自適應的序列并行方法來處理不同序列之間的異質工作負載。圖3展示了一個簡單的例子,表明對于不同長度的序列采用合適的并行策略能夠提高訓練效率。我們的系統會在每輪訓練迭代中捕捉序列長度的異質性,并根據工作負載特征分配最優的異構序列并行策略組合。這種基于異構理念設計的并行范式和訓練系統能夠天然捕捉異構負載的特征,并實現高效訓練。
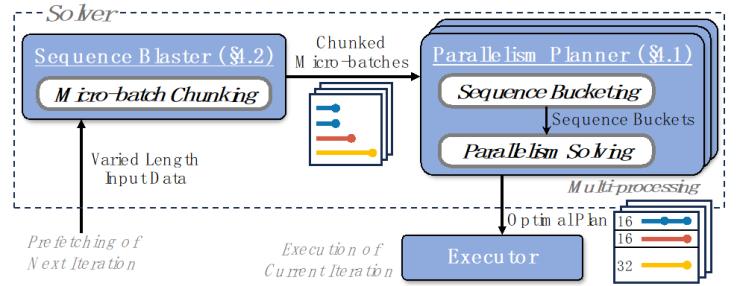
圖4:FlexSP的系統架構圖
圖4展示了我們系統FlexSP的系統架構圖,其由求解器和執行器組成,求解器包含:并行規劃器(Parallelism Planner)負責將異構序列并行的問題建模為線性規劃優化問題并高效地求解,其包括了異構序列并行組的構建和時間均衡的并行組序列分配;序列分組器(Sequence Blaster)負責將輸入的數據批次(Batch),切分為若干個數據微批次(Micro-batch),使得集群的顯存能夠容納每一個微批次,并將每個微批次交由并行規劃器進行異構策略的求解。求解器生成的最優規劃會交由執行器進行訓練。值得一提的是,FlexSP通過數據預取和求解-訓練解耦的方式,將求解開銷(Overlap)完全隱藏于訓練時間中,因此不會引起任何額外開銷。

圖5:FlexSP相比于SOTA系統的端到端性能實驗對比
我們構建了基于異構理念設計的LLM訓練系統FlexSP,并在多個數據集、多種大小模型上進行了實驗,圖5展示了FlexSP相比于SOTA訓練系統(例如Megatron-LM, DeepSpeed)的性能對比,實驗結果表明,我們的系統在性能上比現有的最先進訓練框架提高了最多1.98倍。
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文200余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0