







SIGMOD會議是數據庫領域最具影響力的頂級國際學術會議之一,與VLDB和ICDE并稱為數據庫領域的三大頂級會議。PKU-DAIR實驗室發表于SIGMOD 2024的研究成果《CAFE: Towards Compact, Adaptive, and Fast Embedding for Large-scale Recommendation Models》榮獲了SIGMOD24 Honorable Mention for Best Artifact,該獎項每年僅授予至多三篇文章,旨在表彰那些在可復現性、靈活性和可移植性方面表現卓越的研究工作。
導讀
近年來,深度學習推薦模型(DLRM)中嵌入表的內存需求不斷增長,給模型訓練和部署帶來了巨大的挑戰。現有的嵌入壓縮解決方案無法同時滿足三個關鍵設計要求:高內存效率、低延遲和動態數據分布的適應性。本文提出了CAFE,一種緊湊、自適應和低延遲的嵌入壓縮框架,可以同時滿足上述要求。CAFE的設計理念是動態地為重要的特征(稱為熱特征)分配更多的內存資源,為不重要的特征分配更少的內存。在CAFE中,我們提出了一種快速且輕量級的草圖數據結構,名為HotSketch,用于捕獲特征重要性并實時識別熱特征。對于每個熱特征,我們為其分配唯一的嵌入;對于非熱門特征,我們使用哈希嵌入技術允許多個特征共享一個嵌入。在該設計理念下,我們進一步提出了多級哈希嵌入框架來優化非熱門特征的嵌入表。我們從理論上分析了HotSketch的準確性,并分析了模型的收斂性。實驗表明,CAFE顯著優于現有的嵌入壓縮方法,在10000倍的壓縮比下,在Criteo Kaggle數據集和CriteoTB數據集上的測試AUC分別提高了3.92%和3.68%。
一、問題背景
近年來,嵌入技術廣泛應用于數據庫領域,其中深度學習推薦模型(DLRM)是嵌入技術最重要的應用之一。典型的DLRM將分類特征向量化為可學習的嵌入,然后將嵌入與其他數值特征一起喂給下游神經網絡。最近,嵌入表的內存需求隨著DLRM分類特征數量的指數級增長而增長,給各種應用帶來了巨大的存儲挑戰。在本文中,我們重點關注壓縮超大規模DLRM的嵌入表。DLRM有離線訓練和在線訓練兩種范式。離線訓練時,預先收集訓練數據,并在整個訓練過程后部署模型以供使用。在線訓練中,訓練數據是實時生成的,模型同時更新參數并服務請求。本文主要針對在線訓練的場景,因為在線訓練的難度更大,且在線訓練的壓縮方法可以直接應用于離線訓練。在線訓練中的嵌入壓縮有三個重要的設計要求:
- 高內存效率。為了在內存限制內保持模型質量,一種方案是使用分布式實例,但它們會帶來大量的通信開銷。此外,嵌入表的訓練和部署通常發生在存儲容量較小的邊緣或終端設備上,使得內存問題更加嚴重。另一方面,由于模型質量直接影響利潤,即使AUC(ROC 曲線下面積)0.001的微小變化也會帶來相當大的對利潤的影響。因此,我們需要保持模型質量的內存高效壓縮方法。
- 低延遲。延遲是服務質量的關鍵指標,因此嵌入的壓縮方法必須足夠快,以避免引入顯著的延遲。
- 對數據分布變化的適應性。在線訓練中,數據分布并不像離線訓練那樣固定,一般會隨著時間動態變化。我們需要適合在線訓練的自適應壓縮方法。
現有的行壓縮方法可以分為基于哈希和自適應方法兩類。基于哈希的方法利用簡單的哈希函數將特征映射到具有沖突的嵌入中[1],盡管它們簡單易用,但預先確定的哈希函數會扭曲特征的語義信息,導致模型精度大幅下降;集成特征頻率信息[2]可以提高離線訓練中基于哈希方法的模型質量,但不能應用于在線訓練。自適應方法在訓練過程中識別重要特征以適應在線訓練[3],但現有方法的壓縮率受到重要性分數存儲的限制,導致內存效率較低,且額外的檢查、采樣操作會增加整體延遲。總之,現有方法無法同時滿足所有的三個關鍵要求。
二、CAFE設計方案
1. 總體流程
我們提出的嵌入框架CAFE能夠同時滿足高內存效率、低延遲、適應數據分布動態變化三個要求。CAFE的核心思想是動態區分重要特征(稱為熱特征)和不重要特征(稱為非熱特征),并為熱特征分配更多的資源。具體來說,根據我們的理論推導,我們使用梯度的L2范數定義特征的重要性得分。我們觀察到,在大多數訓練數據中,特征重要性遵循高度傾斜的分布,其中大多數特征的重要性得分較小,只有一小部分熱門特征非常重要。如圖1所示,Criteo Kaggle數據集和CriteoTB數據集中的特征重要性分布分別近似參數1.05和1.1的Zipf分布。因此,CAFE為熱點特征的嵌入分配更多的內存,為非熱點特征的嵌入分配更少的內存,從而在嵌入表的內存使用量不變的情況下顯著提高模型質量。 圖2是CAFE框架的示意圖,在CAFE 中,我們提出了一種新穎的HotSketch算法,用于實時記錄top-k熱特征的重要性。在每次訓練迭代中,我們首先在HotSketch里查詢輸入樣本中的每個特征,重要性分數超過閾值的視為熱門特征;然后我們分別查找熱門特征和非熱門特征的嵌入,我們給熱門特征分配唯一的嵌入,而讓多個非熱門特征共享一個嵌入;隨著訓練數據分布的變化,熱門特征和非熱門特征之間可以互相遷移;在神經網絡反向階段,我們使用特征的梯度范數來更新特征重要性。
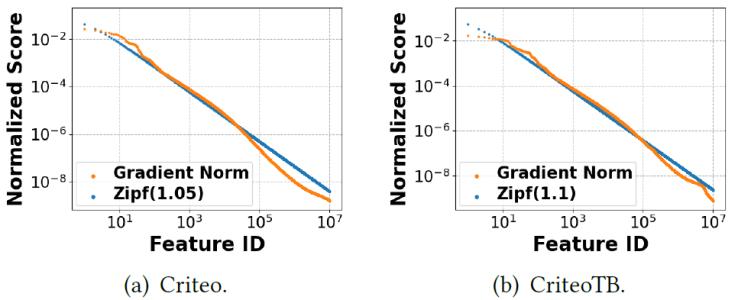
圖1. 特征重要性分布
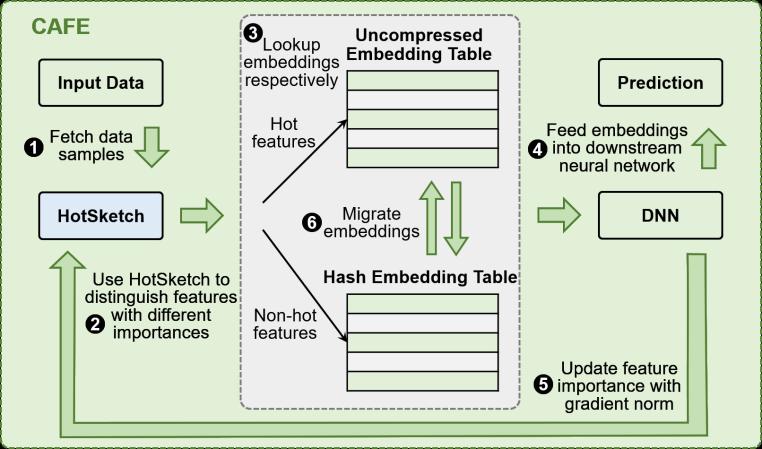
圖2. CAFE示意圖
2. HotSketch算法
HotSketch算法旨在訓練中識別高重要性分數的熱門特征,這本質上是在流數據中查找top-k頻繁項(特征)的問題。目前,Space-Saving[4]是解決該問題最受認可的算法,它在排序的雙向鏈表中維護頻繁項,并使用哈希表來索引。然而,該哈希表不僅使內存使用量增加了一倍,而且指針操作引起的大量內存訪問導致時間效率低下。我們提出的HotSketch刪除了哈希表,同時仍然保持o(1)時間復雜度,并很好地繼承了Space-Saving的理論結果。
數據結構:如圖3所示,HotSketch由多個桶組成,我們使用哈希函數將特征映射到桶中。 每個桶包含多個槽,其中每個槽都存儲一個特征及其重要性分數。
插入:對于每個傳入特征,我們首先計算哈希函數來定位桶,并遇到三種可能的情況:(1) 該特征記錄在桶中,我們將新分數添加到其重要性得分上;(2)桶中沒有記錄該特征且存在空槽,那么我們將該特征和分數插入到空槽中;(3)桶已滿且未記錄該特征,那么我們找到得分最小的特征替換為插入的特征并添加分數。
討論:HotSketch具有以下優點:(1)HotSketch插入速度快,具有o(1) 時間復雜度,并且只有一次內存訪問;(2) HotSketch內存效率高,它不存儲指針,并且短暫冷啟動后不會出現空槽;(3)HotSketch對硬件友好,可以通過多線程和SIMD進行加速,從而實現數據并行性。
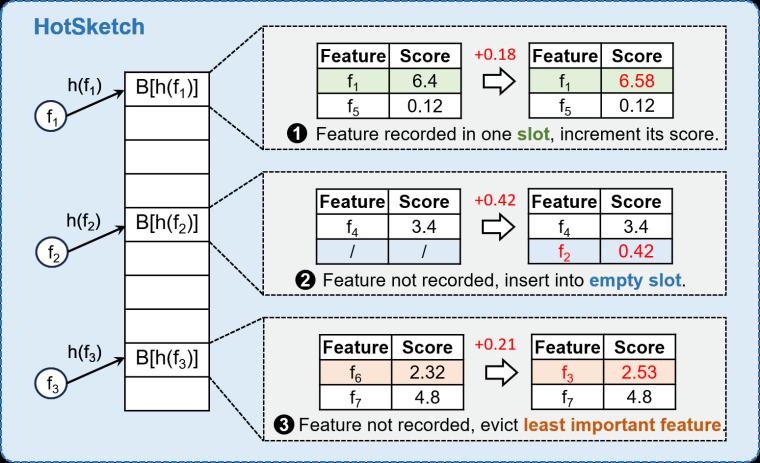
圖3. HotSketch示意圖
3. 遷移策略
在DLRM的在線訓練過程中,特征重要性的分布隨著數據分布的變化而波動,這意味著在整個訓練過程中熱點特征并不是恒定的。HotSketch已經記錄了特征重要性,自然可以通過嵌入表之間的嵌入遷移來支持動態熱特征。我們設置了一個閾值來區分熱點特征,幾乎每個首次達到HotSketch的特征都被視為非熱門特征。當非熱門特征的重要性得分超過閾值時,它會轉變為熱門特征,并且其嵌入將從共享表遷移出來,確保特征的表示在整個訓練過程中保持平滑;相反,HotSketch中特征的重要性會隨時間進行衰減,當熱門特征的重要性得分低于閾值時,它就變成非熱門特征,考慮到新遷移的非熱特征不再重要,因此我們簡單地忽略其原始的獨占嵌入,而使用共享嵌入。通過在HotSketch中設置合適的閾值,我們能夠保持適度的遷移頻率從而使模型適應分布的變化,而不會對收斂和延遲產生負面影響。
4. 多級哈希嵌入
非熱特征的數量遠超熱門特征,鑒于這些非熱特征的重要性得分也符合高度傾斜的Zipf分布,因此我們可以根據其重要性進一步分隔并分配不同的哈希嵌入表。如圖4所示,我們將非熱門特征劃分為不同重要性級別,并為它們分配來自多個表的不同數量的嵌入。簡單起見,我們關注2級哈希嵌入,其中非熱特征分為中等特征和冷特征。我們擴展了HotSketch的功能,以估計中等特征的重要性分數。由于中等特征比冷特征更重要,我們賦予它們兩個不同哈希嵌入表中的兩個嵌入向量,而冷特征僅查找單個嵌入向量。
圖4展示了一個示例。(1)輸入特征f1、f2、f3中,f1的得分大于熱閾值,f2的得分大于中閾值,f3的得分低于閾值,因此它們分別被分為熱特征、中特征和冷特征;(2) 熱特征和冷特征查找嵌入向量的方式不變;(3)中特征從兩個哈希嵌入表中查找兩個嵌入向量,并通過池化過程獲得最終的嵌入。為了確保訓練過程保持平滑,當一個特征在中類和冷類之間遷移時,它總是從第一個嵌入表中檢索相同的嵌入向量。對于池化操作,在實踐中,我們發現嵌入的簡單求和效果很好,因為特征的嵌入向量總是在相同的方向上更新。多級哈希嵌入的設計基于這樣的觀察:唯一嵌入是一種沒有信息丟失的綜合表示,而對于哈希嵌入,涉及的嵌入數量越多,沖突越少,信息量越多。
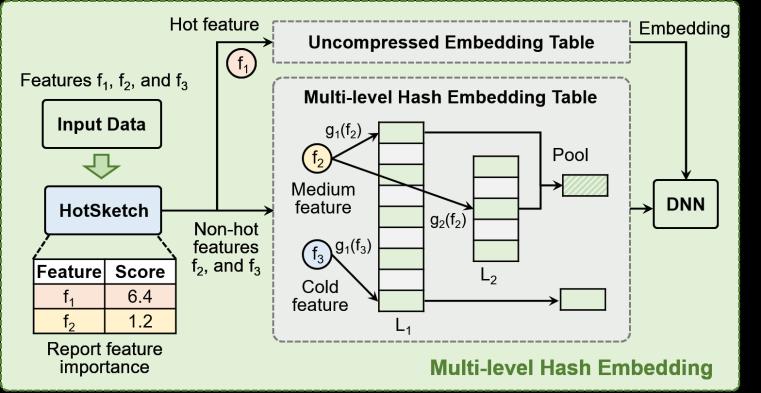
圖4. 多級哈希嵌入示意圖
三、實現
我們將CAFE實現為基于PyTorch的插件嵌入層模塊,可以直接替換任何基于PyTorch的推薦模型中的原始Embedding模塊。
CAFE后端:我們用C++實現HotSketch算法以減少總體延遲,并使用PyTorch實現CAFE的其余部分。我們HotSketch中桶的數量設置為預先確定的熱門特征數量,每個桶有4個槽;我們對所有特征字段使用一個HotSketch結構,而不是每個字段一個結構,因為跨字段的熱門特征分布不明確,最好直接用重要性分數來處理。
容錯性:我們將所有HotSketch的狀態注冊為CAFE的PyTorch模塊中的buffer,使其可以與模型參數一起保存和加載。這種簡單的設計不需要額外的修改,使帶有CAFE的DLRM能夠使用檢查點進行訓練和推理。
內存管理:考慮到HotSketch不是計算密集型任務,我們將整個HotSketch結構放在CPU上。CAFE的嵌入模塊基于PyTorch運算符構建,可以在任何支持PyTorch的加速器(包括 CPU、GPU)上運行。
四、實驗結果
我們用三個模型DLRM[5]、WDL[6]、DCN[7]在四個數據集Criteo,CriteoTB,Avazu,KDD12上做了實驗。我們將CAFE與Hash Embedding[1]、Q-R Trick[8]、AdaEmbed[3]、MDE[9]進行了比較。
1、模型質量比較
我們用測試AUC和訓練loss分別表示離線和在線場景下的模型質量。如圖5所示,相比Hash Embedding、Q-R Trick、MDE方法,CAFE能夠在同樣的壓縮率下達到最好的模型質量,且在訓練過程中一直保持更低的訓練loss。AdaEmbed是一個自適應方法,在低壓縮率場景下有很好的效果,而CAFE不僅能夠達到更高的壓縮率,還能在低壓縮率下取得和AdaEmbed相當或者更好的效果。
具體而言,所有方法中只有CAFE和Hash能達到極限的10000x壓縮率,而其他方法只能支持較小的壓縮率,例如AdaEmbed和MDE只能支持不到100x的壓縮率。DLRM模型里,在Criteo數據集上,與Hash和Q-R Trick相比,CAFE的測試AUC平均提高了1.79%和0.55%;在CriteoTB數據集上,改進分別為1.304%和0.427%; 在KDD12數據集上,改進分別為1.86%和3.80%。 考慮訓練loss,與Hash和Q-R Trick相比,CAFE在Criteo數據集上降低了2.31%、0.72%,在CriteoTB數據集上降低了1.35%、0.59%,在Avazu數據集上降低了3.34%、0.76%。與AdaEmbed相比,CAFE在Criteo數據集上達到了幾乎相同的測試AUC和訓練損失,在CriteoTB數據集上提升了0.04%的測試AUC和減少0.12%的訓練損失,在KDD12數據集上提升了0.82%的測試 AUC,在Avazu數據集上的訓練損失減少了0.83%。
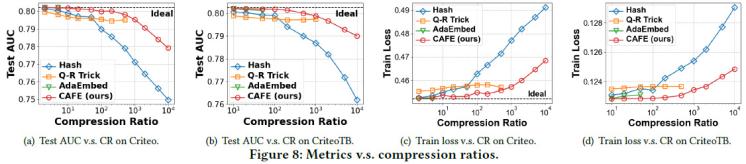
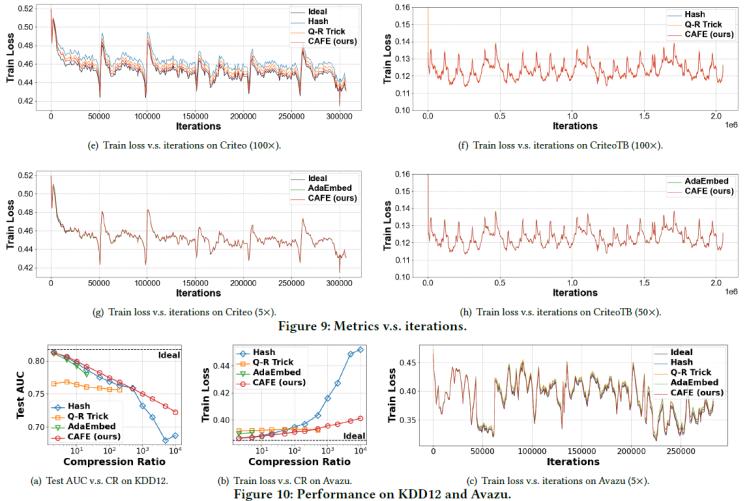

圖5. 模型質量對比
我們進一步查看了多級哈希嵌入的效果,如圖6所示,其中CAFE-ML表示CAFE結合多級哈希嵌入。在不同的壓縮比下,CAFE-ML始終比CAFE表現更好,測試AUC提高了0.08%,訓練損失降低了0.25%。CAFE-ML在較小的壓縮比下表現尤其出色,在100倍壓縮比下幾乎沒有造成性能下降。這是因為CAFE-ML在小壓縮比下為多級哈希嵌入表分配了更多的內存,使得中等特征的表示更加精確。
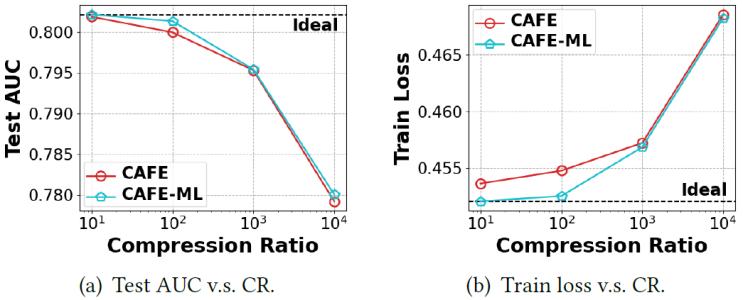
圖6. 比較多級哈希嵌入
2、吞吐量對比
我們在圖7中測試了每種方法的吞吐量,實驗是在壓縮率為10x的CriteoTB數據集上進行的。由于不同方法的數據加載時間和DNN計算時間是相同的,因此差異僅在于嵌入層的操作。與未壓縮的嵌入操作相比,Hash僅需要額外的模運算,因此是訓練和推理中最快的方法。Q-R Trick只額外引入了哈希過程和嵌入向量的聚合,而MDE引入了矩陣乘法、但需要更少的內存訪問來獲取嵌入參數,因此這兩個方法也有較高吞吐量。為了適應在線場景,AdaEmbed和CAFE引入了嵌入的動態調整,即重新分配或遷移,從而導致吞吐量降低。AdaEmbed會定期采樣數千個數據來確定是否重新分配,帶來較大時間開銷;相比之下,CAFE在HotSketch中的計算開銷可以忽略不計。與AdaEmbed相比,CAFE的訓練吞吐量提高了33.97%,推理吞吐量提高了1.20%。
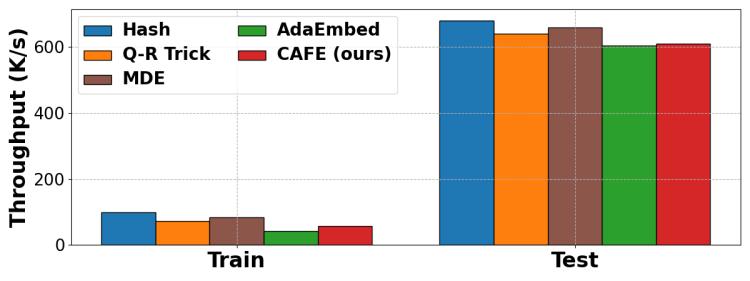
圖7. 吞吐量對比
3、HotSketch評測
桶中槽數的影響(圖8a-b):我們記錄使用不同槽數的HotSketch的召回率和吞吐量。實驗使用Criteo數據集上1000x壓縮率下的熱門特征數量作為k。在圖8a中,召回隨著存儲變大而增加。根據我們的理論推導(見論文推論3.5),給定參數1.05到1.1的Zipf分布,每個桶的最佳槽數位于11到21。因此,槽數為8和16比4和32表現出更好的召回率。圖 8b中所示的序列化插入(寫入)和查詢(讀取)的吞吐量約為1e7,比DLRM本身的吞吐大得多。考慮到我們在實踐中可以并行化操作,HotSketch只占訓練和推理的一小部分。隨著槽數量的增加,吞吐量會下降,因為需要更多的時間在桶內進行比較。權衡召回率和吞吐量,我們在實現中采用每個桶4個槽,此時的模型質量已經足夠好。
尋找實時top-k特征(圖8c-d):我們進行實驗來評估HotSketch在線訓練中尋找兩類實時熱門特征的性能:最新的top-k特征,以及前一個時間窗口中的top-k特征。這兩類top-k特征在在線訓練過程中隨著數據分布的變化而變化,因此可以有效體現HotSketch適應動態工作負載的能力。實驗在 Criteo 上進行,使用6天的在線訓練數據,滑動窗口大小為0.5天。圖8c-d顯示了HotSketch在不同壓縮比下在線訓練時的實時召回率,始終滿足>90%,這意味著它可以很好地跟上不斷變化的數據分布。

圖8. HotSketch評測
五、總結
在本文中,我們提出了CAFE,一種緊湊、自適應且快速的嵌入壓縮方法,它滿足三個基本設計要求:高內存效率、低延遲和對動態數據分布的適應性。我們引入了一種輕量數據結構HotSketch記錄特征的重要性分數,它產生的時間開銷可以忽略不計,并且其內存消耗明顯低于原始嵌入表。通過將獨占嵌入分配給一小組重要特征,并將共享嵌入分配給其他不太重要的特征,我們在有限的內存約束內實現了卓越的模型質量。為了適應在線訓練過程中的動態數據分布,我們采用了基于HotSketch的嵌入遷移策略。我們通過多級哈希嵌入進一步優化CAFE,創建更細粒度的重要性組。實驗結果表明,CAFE優于現有方法,在Criteo和CriteoTB數據集上10000x壓縮比下,測試AUC分別提高了3.92%、3.68%,訓練損失降低了4.61%、3.24%,在離線訓練和在線訓練中均表現出優異的性能。
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文200余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0