







A-Tune-Online: Efficient and QoS-aware Online Configuration Tuning for Dynamic Workloads
作者:Yu Shen, Beicheng Xu, Yupeng Lu, Donghui Chen, Huaijun Jiang, Zhipeng Xie, Senbo Fu, Nan Zhang, Yuxin Ren, Ning Jia, Xinwei Hu, Bin Cui
Github鏈接:https://github.com/PKU-DAIR/A-Tune-Online
1. 問題背景與動機
現代在線服務(如數據庫、編譯器、分布式系統等)需要處理動態變化的負載,例如白天以交互式查詢為主,夜間轉為批量處理任務,或突發流量導致的負載波動。傳統靜態調優方法假設負載固定,無法適應這種動態性,導致歷史最優配置在新負載下性能下降甚至失效。因此,在線配置調優系統需要滿足三個核心目標:動態性(快速適應負載變化)、效率(低調優開銷)和QoS保障(避免性能劣化)。然而,現有在線調優方法因未能有效解決歷史數據干擾和負載變化檢測問題,在實際場景中表現不佳。
現有在線調優方法主要分為兩類:一類(如Rover[1]、Online-Tune[2])假設負載變化微小,持續復用全部歷史觀測數據優化,但不同負載的性能特征可能差異極大甚至負相關,導致當前調優被誤導,收斂效率低下;另一類(如OnlineTune[3])嘗試通過無監督聚類分割歷史數據,但聚類準確性有限,誤分類的觀測數據仍會污染模型。此外,這些方法缺乏顯式且魯棒的負載變化檢測機制。
在線負載通常具有周期性或階段性穩定的特點(如一種負載持續運行一段時間后切換),A-Tune-Online的核心思路是:通過多階段負載檢測精準觸發優化重啟,隔離不相關歷史數據;結合相似任務知識遷移加速重啟后的收斂;并利用置信區間構建安全區域保障QoS。實驗表明,其負載切換檢測準確率和最終性能均顯著優于現有方法。
2. 在線調優流程
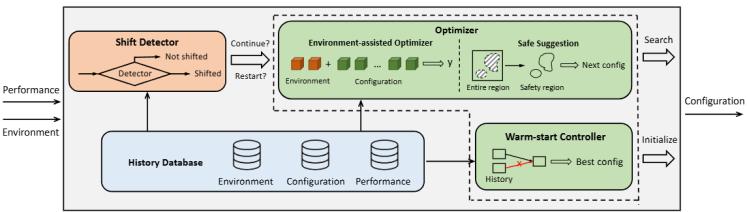
圖1. A-Tune-Online系統流程圖
(1)流程概述
如圖1所示,A-Tune-Online的在線調優流程是一個基于環境感知的動態優化系統。系統通過客戶端持續采集兩類關鍵環境變量:一類是通用系統指標,包括CPU利用率、內存使用率等基礎資源指標;另一類是應用特定指標,如Spark執行器的任務執行時間、數據庫查詢類型分布等。這些環境變量通過日志文件采集,既保證了數據的可獲取性,又避免了涉及隱私的高層信息泄露。
在服務器端,系統以環境變量為核心構建了完整的調優閉環。每次迭代時,服務器接收客戶端上傳的環境變量和性能數據,并將其存入歷史數據庫。① 系統首先采用多指標多階段負載檢測器來分析環境變量的變化:先通過基于規則的方法快速檢測潛在變化,再通過回放驗證確保檢測準確性。當環境變量顯示負載發生顯著變化時,系統會觸發重啟優化流程。② 此時基于機器學習相似性的雙預熱啟動機制會從歷史數據中篩選最相似的任務環境特征,為新一輪優化提供熱啟動。之后 ③ 若環境變量未顯示顯著變化,則使用置信下界增強的QoS感知貝葉斯優化,基于當前環境特征構建概率隨機森林模型,該模型能同時考慮配置參數和環境變量的交互影響,從而生成既安全又高效的配置推薦。
(2)多指標多階段負載檢測器
這一設計直接針對現有方法負載檢測精度不足的問題。通過結合規則基檢測和回放基檢測,系統既能快速響應潛在變化,又能通過回放驗證確保檢測準確性。這種高精度的檢測機制為后續優化提供了可靠的基礎,避免了不必要的重啟或遺漏關鍵變化。當檢測到負載變化后,系統會觸發優化重啟。
A-Tune-Online采用了一種創新的多階段負載變化檢測機制,以應對動態工作負載帶來的調優挑戰。該系統首先通過一個基于多指標規則的高精度檢測器進行初步判斷,只有當所有預設指標(如CPU利用率、內存使用率等系統指標和特定應用指標)都一致表明負載變化時,才會觸發變化信號。這種"全票通過"的設計理念顯著降低了誤報率,確保只有在負載確實發生變化時才重啟優化過程。
當第一階段的保守檢測未能達成一致判斷但部分指標顯示異常時,系統會啟動更精確但計算成本較高的回放式檢測作為第二道防線。這種分階段的設計既保證了檢測的實時性,又通過逐步深入的驗證確保了結果的可靠性。檢測過程中,系統運用了嚴密的數學理論來保證多指標聯合判斷的精度下限,并通過精心選擇的指標組合來進一步提升檢測性能。一旦任一階段確認負載變化,系統就會立即終止當前優化過程,并針對新負載啟動全新的調優流程。
這種多階段檢測策略的創新之處在于:它通過規則基檢測的快速篩選和回放檢測的精確驗證相結合,在保證高精度的同時兼顧了召回率,有效解決了傳統方法在動態負載場景下要么過于敏感(導致頻繁無效重啟)、要么過于遲鈍(錯過重要變化)的兩難問題。實驗證明,該檢測機制能準確識別各種類型的負載變化,為后續的優化重啟決策提供了可靠依據。
(3)基于相似性的雙預熱啟動機制。
A-Tune-Online采用了一種基于任務相似性的熱啟動策略來優化重啟過程,當檢測到負載變化時,系統會立即啟動新調優任務,并針對不同相似度采取差異化的預熱策略,既充分利用了相似任務的知識加速收斂,又有效隔離了不相似任務帶來的負面影響。這一設計使得系統在重啟后平均僅需15.6次迭代即可收斂,大大提升了調優效率。
系統首先構建了一個基于環境向量的任務相似性預測模型,該模型采用LightGBM回歸器,通過分析隨機配置在歷史任務中的表現排序一致性(Kendall-tau相關系數)來量化任務相似度。
在具體實施時,系統采用兩級漸進式預熱機制:第一級配置預熱會選取相似度最高的5個歷史任務,將其最優配置作為新任務的初始候選;第二級模型預熱則僅在最高相似度超過0.65閾值時,直接復用相似任務的代理模型進行前10次迭代的配置推薦。這種雙重機制既充分利用了高相似任務的知識,又通過嚴格的相似度閾值避免了低質量遷移。實驗數據顯示,相似度高于0.65的代理模型在前10次迭代中預測準確性顯著優于新建模型,而10次迭代后新建模型逐漸成熟,此時系統自動切換為基于當前任務觀測的純BO優化。
為確保魯棒性,當訓練數據不足時,系統會降級使用歐氏距離進行任務匹配,并禁用模型級預熱,這種設計使得A-Tune-Online能夠在最差情況下退化為標準BO性能。整個預熱過程結束后,系統將完全依賴當前任務的觀測數據,確保不相似任務的負面影響不會持續存在。
(4)置信下界增強的QoS感知貝葉斯優化。
為確保調優過程的安全性,系統引入了QoS感知機制,傳統貝葉斯優化在探索新配置時可能造成性能下降,而該系統通過構建基于置信下界的安全區域,將采樣限制在性能有保障的范圍內,完全避免了QoS違規。
系統通過構建預測置信下界來量化每個配置的安全程度。基于此,系統動態維護一個安全區域,僅包含那些預測下界超過預設閾值δ的配置(δ通常設為默認配置性能水平)。在每輪迭代中,優化器會從安全區域內選擇預期改進最大的配置進行測試,而非全局最優配置。
這種機制具有雙重優勢:隨著觀測數據積累,安全區域會自適應擴展,既避免了早期盲目探索高風險區域,又不會永久限制搜索空間。實驗表明,該方法能在保證零QoS違規的前提下,實現與無約束優化相當的最終性能,解決了在線調優中安全與探索的根本矛盾。
3. 實驗結果
A-Tune-Online在5個典型場景(MySQL、Redis、Kafka、UnixBench和Spark)進行評測,通過周期切換12-36種不同負載模擬真實動態環境。系統從應用日志提取10維(Kafka)至67維(MySQL)環境向量,每10分鐘采集性能數據并推薦新配置,最多評估40個配置。對比基線包括GP-BO、TPE、OnlineTune等5種調優方法,測試平臺為96核CPU/100G內存服務器。實驗指標涵蓋吞吐量(rps/lps)和運行時等關鍵性能參數。
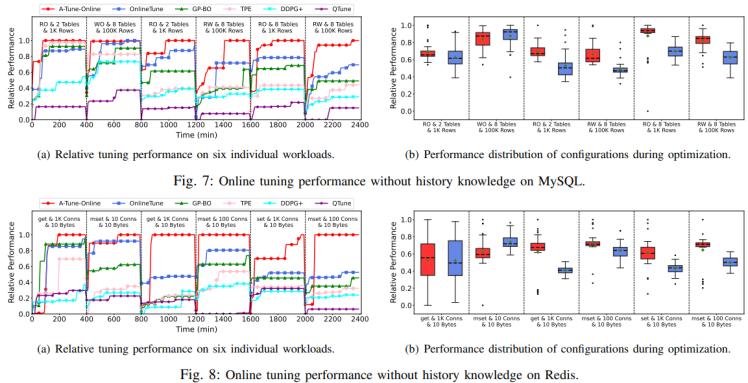
圖2. 無歷史數據實驗結果
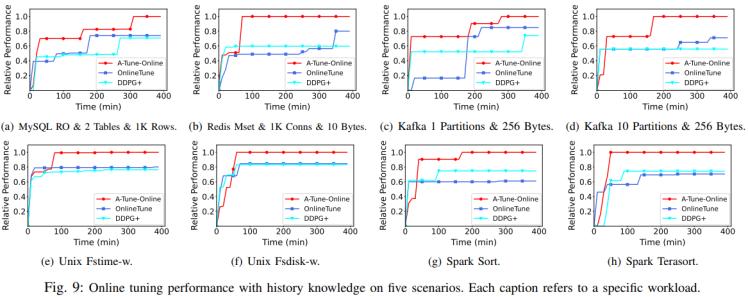
圖3. 有歷史數據實驗結果
實驗首先在無歷史知識的情況下評估各調優算法的表現,如圖2所示。當所有方法都從零開始時,基于貝葉斯優化的方法(如GP-BO、TPE)在初始階段表現優于強化學習方法(DDPG+和QTune),這與前人研究中關于強化學習需要更多初始配置的結論一致。隨著時間推移,A-Tune-Online和OnlineTune憑借對動態負載的處理能力逐漸拉開差距。關鍵數據顯示,A-Tune-Online在MySQL和Redis場景中分別實現了0.88和0.81的負載分類準確率,顯著高于OnlineTune的0.59和0.57,這使其能有效利用97%的相關歷史觀測數據,避免不相似負載的干擾。相比之下,OnlineTune由于依賴不穩定的無監督聚類,性能受到明顯限制。
如圖3,在有歷史知識的情況下,實驗進一步驗證了各方法利用先驗信息的能力。預先使用標準BO為每個場景構建歷史數據庫后,A-Tune-Online展現出更快的收斂速度。在涵蓋MySQL、Redis等五大場景的測試中,該系統相比OnlineTune和DDPG+分別實現了2.86%-13.20%和4.68%-13.18%的性能提升。特別值得注意的是,在Spark任務中僅用5次迭代就找到近優配置,證明其相似任務匹配機制的有效性。效率指標顯示,達到相同性能水平時,A-Tune-Online平均比OnlineTune快2.9倍,比DDPG+快1.72倍。這些結果充分說明,系統設計的雙重熱啟動策略能智能區分負載相似度,在保證安全性的前提下最大化歷史知識的價值。
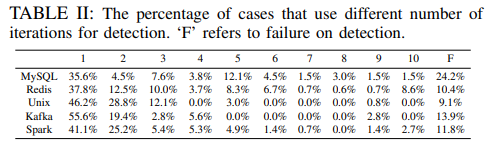
表1.切換檢測召回率
此外,A-Tune-Online的負載變化檢測機制在實驗中展現出卓越的性能表現。如表1所示,該系統的多階段檢測策略在五大測試場景中實現了76%-91%的召回率,其中回放式檢測器平均提升了8%的召回性能。特別值得注意的是,得益于保守設計原則,所有場景下的檢測精度都達到了完美的100%,完全避免了誤報情況。在檢測效率方面,系統平均僅需觸發0.6次回放檢測(耗時約6分鐘),且大多數負載變化能在5次配置評估內被準確識別。這些數據充分驗證了系統設計的規則基檢測與回放基檢測相結合的策略,既保證了檢測的及時性,又確保了判斷的準確性。
4. 總結
A-Tune-Online 是一種面向動態工作負載的在線配置調優系統,能夠同時實現高性能、高效率和 QoS 保障。該系統通過多階段負載突變檢測(結合規則和重放檢測器)精準識別工作負載變化,并觸發優化重啟以避免歷史不相關數據的干擾。為提高重啟后的優化效率,它采用熱啟動技術,利用回歸模型匹配歷史相似負載并復用其配置或代理模型知識。此外,系統通過維護安全區域并優先推薦預期改進最優的配置來確保 QoS。實驗表明,A-Tune-Online 在多種場景下均能準確檢測負載變化、快速適應新負載,并提供比現有系統更優的配置推薦和 QoS 保障。
參考文獻
- Y. Shen, X. Ren, Y. Lu, H. Jiang, H. Xu, D. Peng, Y. Li, W. Zhang, and B. Cui, “Rover: An online spark sql tuning service via generalized transfer learning,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 4800-4812.
- Y. Li, H. Jiang, Y. Shen, Y. Fang, X. Yang, D. Huang, X. Zhang, W. Zhang, C. Zhang, P. Chen et al., “Towards general and efficient online tuning for spark,” Proceedings of the VLDB Endowment, vol. 16, no. 12, pp. 3570-3583, 2023.
- X. Zhang, H. Wu, Y. Li, J. Tan, F. Li, and B. Cui, “Towards dynamic and safe configuration tuning for cloud databases,” in Proceedings of the 2022 International Conference on Management of Data, 2022, pp. 631-645.
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文200余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0