







作者:Peichao Lai, Zhengfeng Zhang, Wentao Zhang, Fangcheng Fu, Bin Cui
Github鏈接:https://github.com/aleversn/GCSE
ACL ( The Annual Meeting of the Association for Computational Linguistics )是自然語言處理(NLP)與計算語言學領域最具影響力的國際學術會議之一,被中國計算機學會(CCF)推薦為 A類會議。ACL 2025 將于7月27日—8月1日在奧地利維也納舉行。
PKU-DAIR實驗室論文《 Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning》被ACL 2025 錄用。
一、問題背景與動機
句子表示學習作為自然語言處理的基礎任務,旨在生成準確的句子嵌入以提升語義推理、檢索和問答等下游任務的性能。基于對比學習的無監督句子嵌入方法因計算效率高且無需人工標注數據,成為當前的研究熱點。該類方法的核心思想是通過對比損失函數,拉近語義相似句子的嵌入距離并推遠不相似句子的距離。然而,其性能高度依賴訓練樣本的數量與質量,在數據增強過程中,如何有效提升樣本的多樣性和純凈度,成為無監督對比學習的關鍵挑戰。
核心挑戰:數據多樣性與噪聲問題
現有方法主要面臨兩大瓶頸:
其一,數據多樣性不足。現有數據增強方法常忽略實體、數量等細粒度知識,導致生成樣本的語義變體有限。傳統規則化方法依賴固定模板修改句子(如簡單詞替換),而基于大語言模型(LLM)的方法(如 SynCSE、MultiCSR)雖通過提示引導生成多樣化樣本,但缺乏對知識的顯式控制,樣本多樣性受限于 LLM 的概率分布,難以覆蓋同一知識的多維度表達(如實體類型、數量級變化)。
其二,數據噪聲過高。無監督場景下,負樣本易包含表面語義相似但實際語義無關的 “假負例樣本”,而 LLM 生成的合成樣本可能因語義分布偏差引入額外噪聲。現有去噪方法(如 MultiCSR 的線性規劃過濾)可能誤刪有價值樣本,導致數據多樣性進一步下降。如圖 1 所示,在 STS-Benchmark 驗證集上,現有方法普遍存在假正例(FP)和假負例(FN)樣本比例失衡的問題,表明假負樣例噪聲已成為影響模型判別能力的關鍵因素。
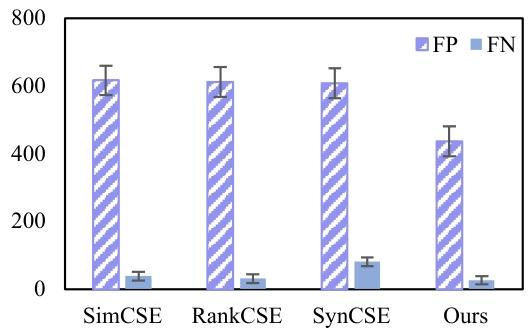
圖1. 不同方法在驗證集上假正例(FP)和假負例(FN)對比
為解決上述問題,本研究提出結合知識圖譜與 LLM 的流水線式結構的數據增強方法,并引入高斯衰減對比學習模型(GCSE)。具體動機包括:
- 顯式建模細粒度知識:通過知識圖譜提取句子中的實體、數量及其關系,引導 LLM 生成包含結構化語義變體的樣本(如實體替換、數量調整),突破傳統方法對全局語義的粗粒度控制,提升樣本多樣性。
- 動態抑制噪聲影響:設計高斯衰減函數調整假負例樣本的梯度權重,在訓練初期降低其對語義空間的扭曲,隨著模型收斂逐步恢復權重,實現噪聲樣本的有效利用而非直接丟棄。
- 提升數據利用效率:在少樣本和輕量級 LLM 場景下實現較高性能,證明了方法對低資源場景的適應性。通過上述創新,本研究旨在為無監督句子嵌入提供一種兼顧多樣性與噪聲影響的解決方案,推動其在實際場景中的應用。
二、數據增強和模型訓練流程

圖2. 數據增強和句子表示訓練工作流
如圖2所示,本方法通過LLM進行數據增強,從源數據中合成新樣本,然后使用經過初始過濾的合成數據訓練GCSE模型。
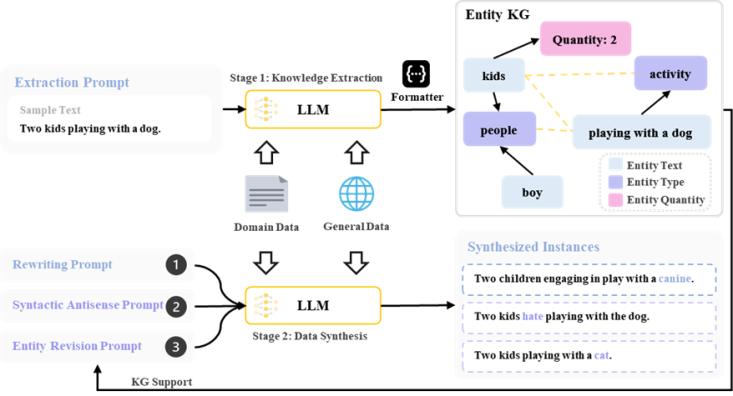 圖3. 基于知識抽取構建實體知識圖譜的數據生成框架
圖3. 基于知識抽取構建實體知識圖譜的數據生成框架
1. 數據增強:知識驅動的樣本合成流程
數據增強模塊旨在通過LLM生成高質量、多樣化的訓練樣本,平衡領域特異性與通用語義空間的適配性。該流程分為知識提取與整合和基于 LLM 的正負樣本合成兩個核心環節,如圖 3 所示。首先,從源數據中提取實體、數量等細粒度知識,構建實體知識圖譜(KG),其中節點包含實體文本、類型及數量(如 “孩子 - 人物 - 兩個”),邊分為硬邊(實體與類型 / 數量的固定關系)和軟邊(同一句子內實體間的關聯)。通過知識圖譜,可系統地捕捉樣本中的結構化信息,為后續合成提供語義約束。
知識提取與圖譜構建
具體而言,通過設計提取提示詞,利用 LLM 從每個樣本中解析出知識集合,每個知識單元包含實體文本、類型和數量。將所有樣本的知識單元整合為實體知識圖譜,其中節點包含所有提取的三元組,通過構建實體和對應實體類型的硬邊(如 “狗 - 動物”)和實體與上下文其他實體的軟邊(如 “狗 - 公園” 的共現關系)連接節點。這種結構化表示允許模型高效識別可替換的實體節點(如同一類型的 “貓”“狗”),確保合成樣本與源樣本的語義關聯性。
基于 LLM 的正負樣本合成
在樣本合成階段,通過三類提示詞引導 LLM 生成多樣化樣本:
- 改寫提示詞:生成正樣本,如通過 “重寫句子但保留原意” 指令生成語義等價變體(如 “兩個孩子和狗玩耍”→“孩童與犬類嬉戲”)。
- 語法反義提示詞:生成語法層面矛盾的負樣本,如通過否定詞或情感反轉構造語義對立句(如 “孩子沒有和狗玩耍”)。
- 實體 / 數量修訂提示詞:基于知識圖譜搜索相鄰節點(如替換 “狗” 為同類型實體 “貓”,或調整數量 “兩個”→“一個”),生成細粒度差異的負樣本。 通過知識圖譜約束實體替換范圍(如僅選擇同類型實體或關聯實體),確保負樣本在表面特征上接近源樣本,但在細粒度語義上存在明確差異,從而提升對比學習的有效性。生成樣本經評估模型初步過濾后,形成最終的訓練數據集。
2. 模型訓練:兩階段對比學習框架
模型訓練過程分為通用對比學習預訓練和帶噪聲抑制的對比學習微調兩個階段,旨在通過漸進式訓練提升模型對語義空間的建模能力。首先,利用通用數據和領域數據預訓練一個評估模型,學習通用語義分布;隨后,將評估模型的結構和參數遷移至 GCSE 模型,并通過高斯衰減函數動態調整難負樣本的影響,實現對合成數據中噪聲的有效抑制。
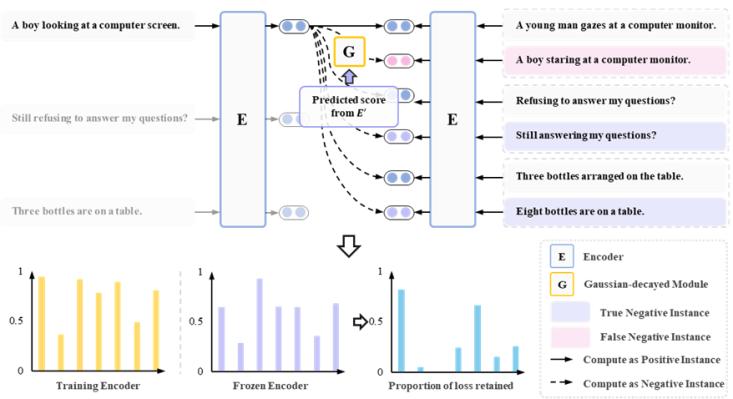 圖4. 基于高斯衰減的GCSE模型批次訓練示例圖
圖4. 基于高斯衰減的GCSE模型批次訓練示例圖
第一階段:通用對比學習預訓練
在預訓練階段,采用標準對比學習框架SimCSE訓練評估模型。對于每個無標簽句子,將其自身通過隨機 dropout 生成兩個不同視圖作為正樣本對,同批次其他句子作為負樣本。損失函數采用 InfoNCE 形式,計算正樣本對的余弦相似度并拉遠與負樣本的距離。此階段通過通用數據(如 Wikipedia)和領域數據的混合訓練,使評估模型學習到均勻的語義分布,為后續噪聲過濾和特征提取提供相對可靠基準。預訓練完成后,評估模型參數被凍結,用于合成數據的質量評估。
第二階段:帶高斯衰減的對比學習微調
在微調階段,GCSE 模型以評估模型為骨干網絡,接收由數據增強流程生成的三元組樣本 。首先通過評估模型過濾合成樣本:
- 正樣本篩選:采用較高閾值保留與源樣本相似度高(如 0.9)的合成句;
- 負樣本篩選:選擇與源樣本相似度相對較高的合成句或隨機批次內負樣本來保留文本多樣性以及易混淆負樣例。對于過濾后的負樣本,引入高斯衰減函數動態調整其梯度權重。該函數根據 GCSE 模型與評估模型對負樣本的相似度預測差異的自動衰減梯度:
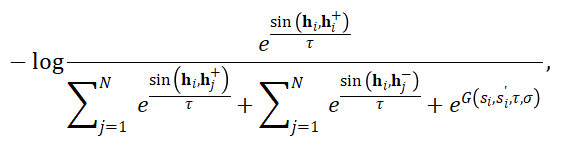
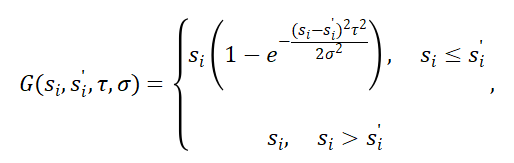
- 在訓練初期,若負樣本被誤判為相似(假負例),期望GCSE對齊評估模型的相似度分數,利用高斯函數抑制其梯度,避免語義空間因假負樣例而發生錯誤變化;隨著訓練推進,若真負樣本的相似度分數與評估模型逐漸加大,其梯度權重將逐步恢復,確保模型最終學會區分細粒度語義差異。此機制在保留樣本多樣性的同時,有效緩解了噪聲對訓練的干擾。
三、實驗結果
實驗數據與場景配置
實驗在兩類場景下展開:一是基于 Wikipedia 文本的默認設置,遵循經典方法合成樣本;二是模擬低資源場景,采用 STS-12(2.2k)、PAWS(3.5k)、SICK(4.5k)等領域無標簽數據與 NLI 通用數據(比例 1:3),驗證模型在有限數據下的性能。數據增強環節利用 ChatGLM3-6B、GPT-3.5 Turbo、Deepseek-V3-0324 等多個參數規模 LLM 生成樣本,覆蓋從 6B 到 32B 參數的本地模型,以測試方法對不同 LLM 的適配性。
模型架構與訓練流程
主干網絡采用 BERT 和 RoBERTa(base/large 版本),訓練分為兩階段:首先通過標準對比學習在混合數據上預訓練評估模型,學習通用語義分布,其參數后續凍結用于合成數據過濾;然后以評估模型為骨干初始化 GCSE,輸入經知識圖譜引導生成的三元組樣本(源句、正樣本、負樣本),通過設定閾值初始過濾高噪聲樣本,并利用高斯衰減函數動態調整難負樣本的梯度權重,平衡噪聲抑制與樣本多樣性。
評估指標與基線對比
核心評估聚焦語義文本相似性(STS)任務,覆蓋 7 個標準子集,以 Spearman 相關系數為指標,并通過 SentEval工具對比包括傳統無監督方法(如 SimCSE、RankCSE)和 LLM 增強方法(SynCSE、MultiCSR)。實驗在 NVIDIA A800 GPU 上完成數據合成,于 8 塊 NVIDIA TITAN RTX GPU 進行模型訓練,確保效率與穩定性。
主要實驗結果
在語義文本相似性(STS)任務上,本文方法展現出顯著的性能優勢。表1結果顯示,基于不同大語言模型(LLM)合成數據的 GCSE 模型在所有主干網絡(BERT、RoBERTa)上均優于現有無監督基線方法。例如,使用 Deepseek-V3-0324 和 GPT-3.5 Turbo 合成樣本的 GCSE 模型在 STS 任務平均得分中表現最佳;即使采用輕量級 LLM(如 ChatGLM3-6B),GCSE 仍能超越 SynCSE、MultiCSR 等先進方法。具體而言,與標準無監督 SimCSE 相比,GCSE(ChatGLM3-6B)在 Base 模型上平均提升 5.40%,在 Large 模型上提升 3.95%;在強基線 RankCSE 基礎上,平均提升 1.90%,驗證了 LLM 數據合成流程的有效性。
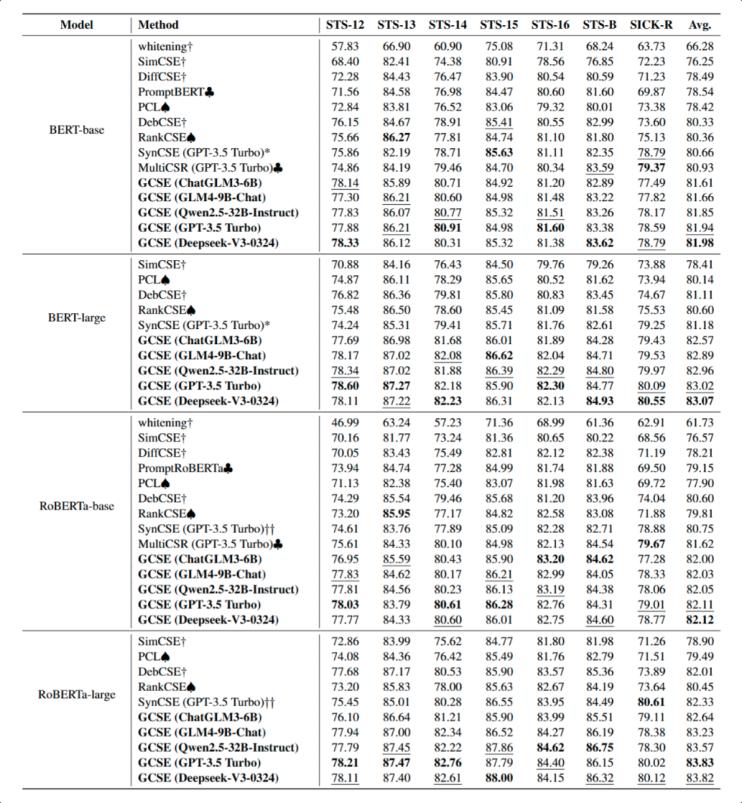
表1: 默認設置下的實驗結果
在模擬低資源、高質量領域數據的場景下(表 1),GCSE 使用僅為 SynCSE 和 MultiCSR 14% 的樣本量,仍實現了更高的平均 Spearman 相關系數。例如,在 BERT-base 模型上,GCSE(GPT-3.5 Turbo)平均得分達 81.92,顯著優于依賴全量 NLI 數據的基線方法,表明本文提出的數據合成策略和領域樣本選擇方法能高效利用有限數據,提升模型對目標領域的語義建模能力。
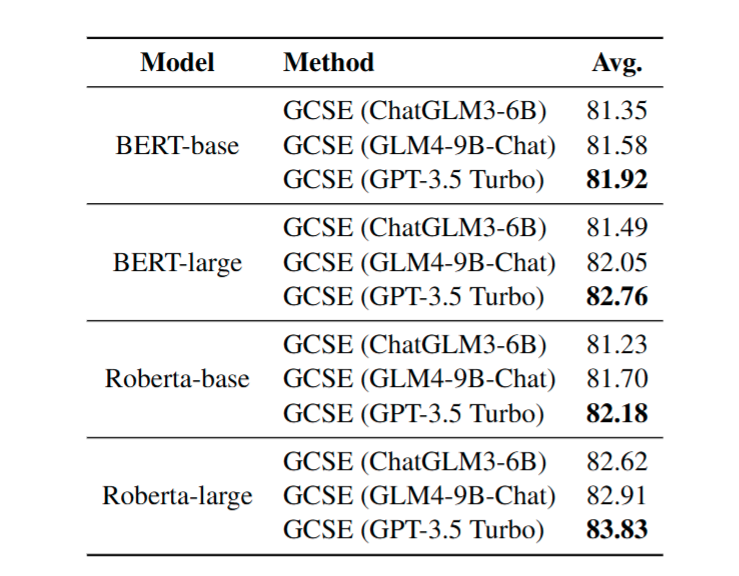
表2: 模擬低資源場景下的實驗結果
此外,GCSE 在不同規模的 LLM 下均表現出魯棒性:從 6B 參數的 ChatGLM3 到 32B 參數的 Qwen2.5,模型性能隨 LLM 規模增長呈上升趨勢,但即使使用較小 LLM,GCSE 仍能通過知識驅動的數據增強彌補模型能力的不足,在 STS 任務中保持領先。實驗結果表明,本文方法在數據效率和模型泛化性上實現了雙重突破,為無監督句子嵌入提供了新的性能基準。
四、總 結
本研究提出知識驅動的數據增強框架與高斯衰減對比學習模型(GCSE),通過提取實體、數量等細粒度知識構建知識圖譜來指導LLM生成多樣化樣本,并創新性地采用高斯衰減梯度調節機制:在訓練初期降低困難負樣本的梯度權重,根據其與評估模型的分布偏差動態調整梯度影響,從而在提升數據多樣性的同時有效抑制噪聲干擾。實驗表明,GCSE在STS任務上能夠以更少數據量和較小模型參數規模實現顯著的性能提升,實驗在BERT和RoBERTa系列模型上取得了優于現有方法的平均性能,為細粒度句子表示學習提供了兼顧語義多樣性與噪聲控制能力的新范式。
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文200余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0