







ICCV (The International Conference on Computer Vision ) 是計算機視覺領域的國際學術會議之一,也是中國計算機學會評定的A類會議。ICCV每兩年舉辦一次。ICCV 2025將于2025年10月19日-23日在美國夏威夷會議中心舉行。 PKU-DAIR實驗室《Training-free and Adaptive Sparse Attention for Efficient Long Video Generation》論文被ICCV 2025錄用。
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
作者:Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, Bin CUI
論文鏈接:https://arxiv.org/abs/2502.21079
1. 背景與挑戰:
在視頻生成領域,Diffusion Transformers(DiTs)已經成為一種先進的生成模型框架,在多模態生成任務中取得顯著的效果。然而,盡管DiTs在生成高質量視頻方面表現出色,但生成長視頻時仍面臨著巨大的計算挑戰,特別是在模型的Attention計算方面。比如,用HunyuanVideo生成一個8s 720p的視頻需要大概1h的時間,其中Attention計算占80%。如圖1所示,Attention的占比會隨著視頻長度的增加而不斷增加,成為主要的瓶頸。
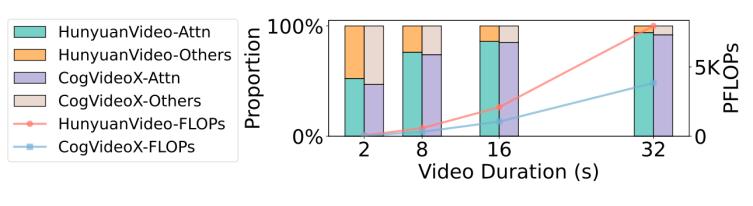
圖1. 不同視頻時長所需的總FLOPs和Attention占用FLOPs的比例
雖然很多稀疏注意力 (Sparse Attention) 方法已被提出以減輕Attention計算,但這些方法普遍面臨一個問題:DiTs中的稀疏范式 (Sparse Pattern) 具有高度的動態性和不規則性,現有的靜態模式和離線搜索方法無法有效適應這些變化,而現有的動態稀疏范式雖然能夠適應變化,但他們大多依賴近似搜索方法,精度和效率很低,不能實時精準地識別稀疏范式,進而影響視頻生成的速度和質量。
2. 方法:
上面分析得出,現有的稀疏注意力在DiT長視頻生成的計算中無法兼顧精度和效率。為此,我們在本論文中提出了AdaSpa,首個「在線精確搜索+動態范式」的稀疏注意力方法,能在高效加速長視頻生成的同時,保持極高的精度。
我們首先詳細分析了DiT視頻生成中稀疏范式的特點:1) DiT適用于用塊狀稀疏注意力來建模,2) DiT稀疏范式隨著去噪步數不變,3) DiT稀疏范式隨著Head變化較大。利用以上特點,我們構建了AdaSpa,它是一種結合「動態塊化范式 + 在線精確搜索 + 頭自適應」的新型稀疏注意力機制。利用DiT去噪步數之間的相似性,在某些步驟進行精確的在線稀疏范式搜索,在后續步驟中復用這些范式,以此來減少搜索開銷和增加搜索精度,達到精度和效率的雙重提升。
其架構圖如圖2所示:
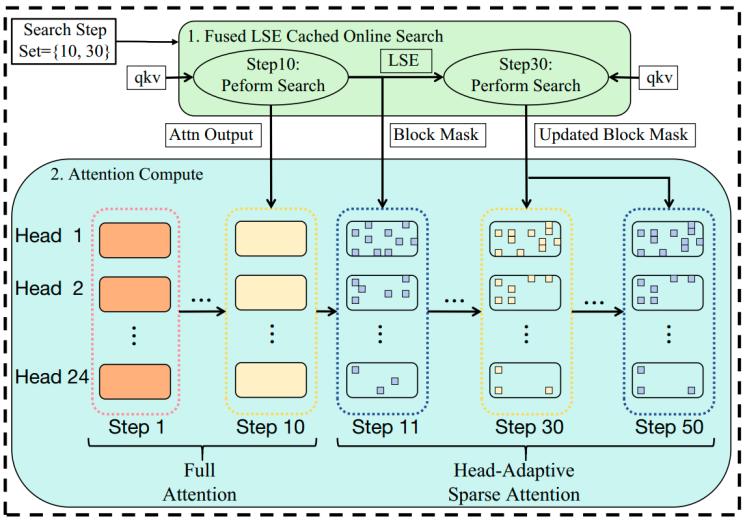
圖2. AdaSpa架構圖
具體來說,AdaSpa在預定義的搜索步驟 (Search Step Set) 利用自實現的高效的Fused LSE-Cached Online Search kernel進行精確搜索,在其他步驟復用這些精確范式進行稀疏注意力計算。 Fused LSE-Cached Online Search kernel將搜索與FlashAttention2耦合,在搜索步同時計算注意力輸出并緩存 LSE,后續搜索復用緩存,進一步減少搜索時間。其次,根據不同Head的稀疏度不同,我們引入 Head-Adaptive Block Sparse Attention,根據各Head召回率動態調整稀疏度以以提高精度并保證kernel的負載均衡。
3. 實驗:
表1. AdaSpa和其他方法的質量和延遲的定量評估結果
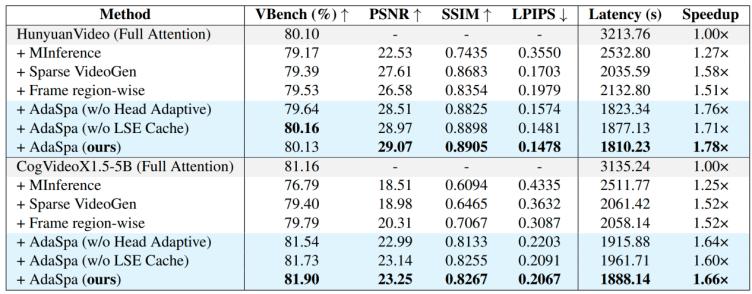
為了驗證我們方法的有效性,我們與LLM中最先進的的稀疏注意力方法MInference和DiT中最先進的的稀疏注意力方法Sparse VideoGen做了對比,實驗表明我們的方法在速度和效率上均超過了之前的方法。
在本論文中,我們對DiTs生成視頻注意力機制中的稀疏特性進行全面分析。基于這些觀察和分析,我們提出了一種全新的稀疏注意力AdaSpa方法,該方法具備動態模式與在線精確搜索的能力,能夠加速長視頻的生成。實驗結果表明,AdaSpa在保持生成視頻高質量的同時,實現1.78倍的效率提升。
實驗室簡介
北京大學數據與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數據庫系統、大數據管理與分析、人工智能等領域的前沿研究,在理論和技術創新以及系統研發上取得多項成果,已在國際頂級學術會議和期刊發表學術論文200余篇,發布多個開源項目。課題組同學曾數十次獲得包括CCF優博、ACM中國優博、北大優博、微軟學者、蘋果獎學金、谷歌獎學金等榮譽。PKU-DAIR實驗室持續與工業界展開卓有成效的合作,與騰訊、阿里巴巴、蘋果、微軟、百度、快手、中興通訊等多家知名企業開展項目合作和前沿探索,解決實際問題,進行科研成果的轉化落地。


評論 0